Site web - Source de données
Utilisez une seule page web ou un site web entier comme source de données. Cette section explique comment configurer l'exploration du site web.
Cliquez sur Site web pour ajouter une page web ou un site web comme source de données :
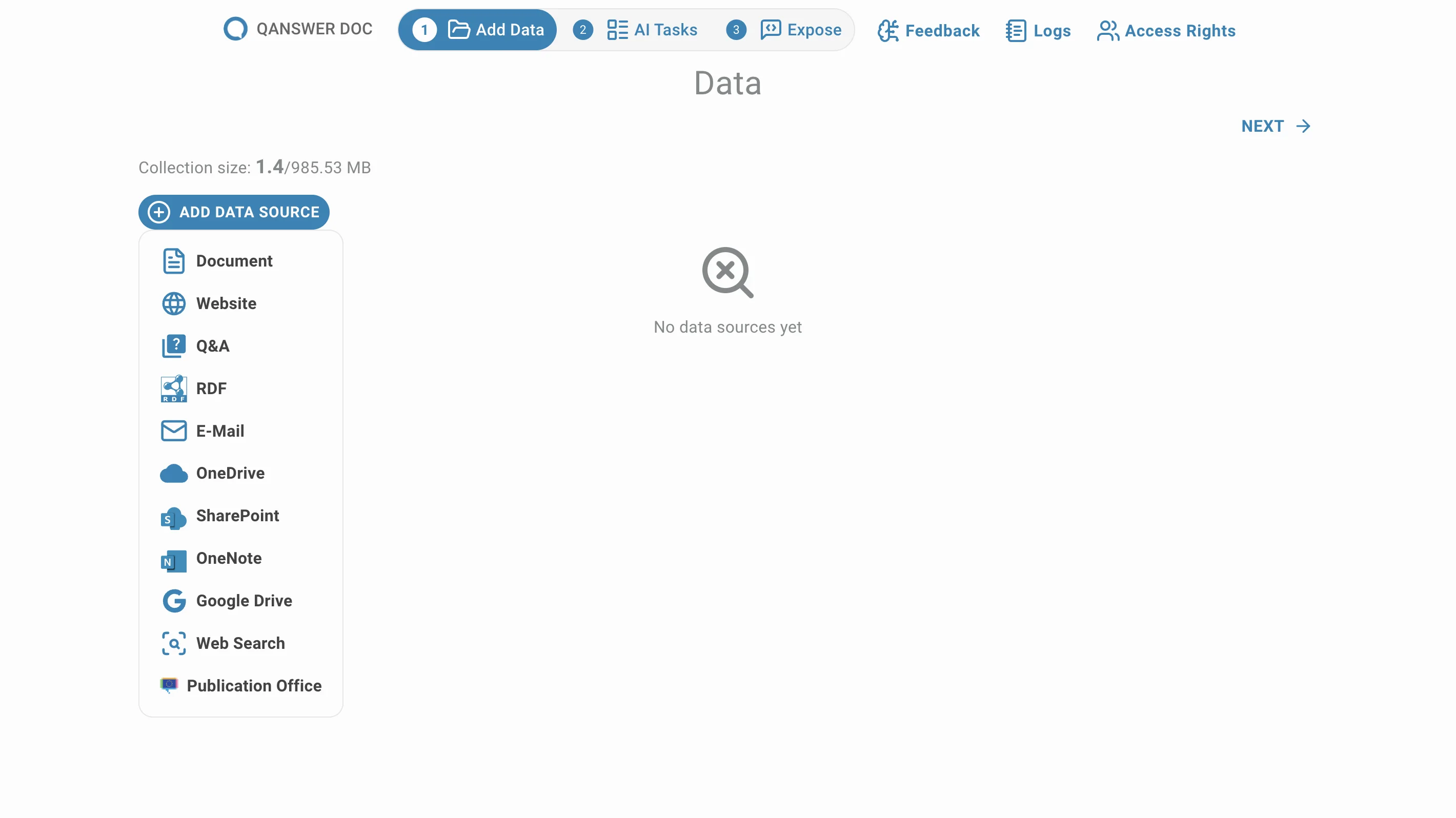
La page suivante s'ouvre :
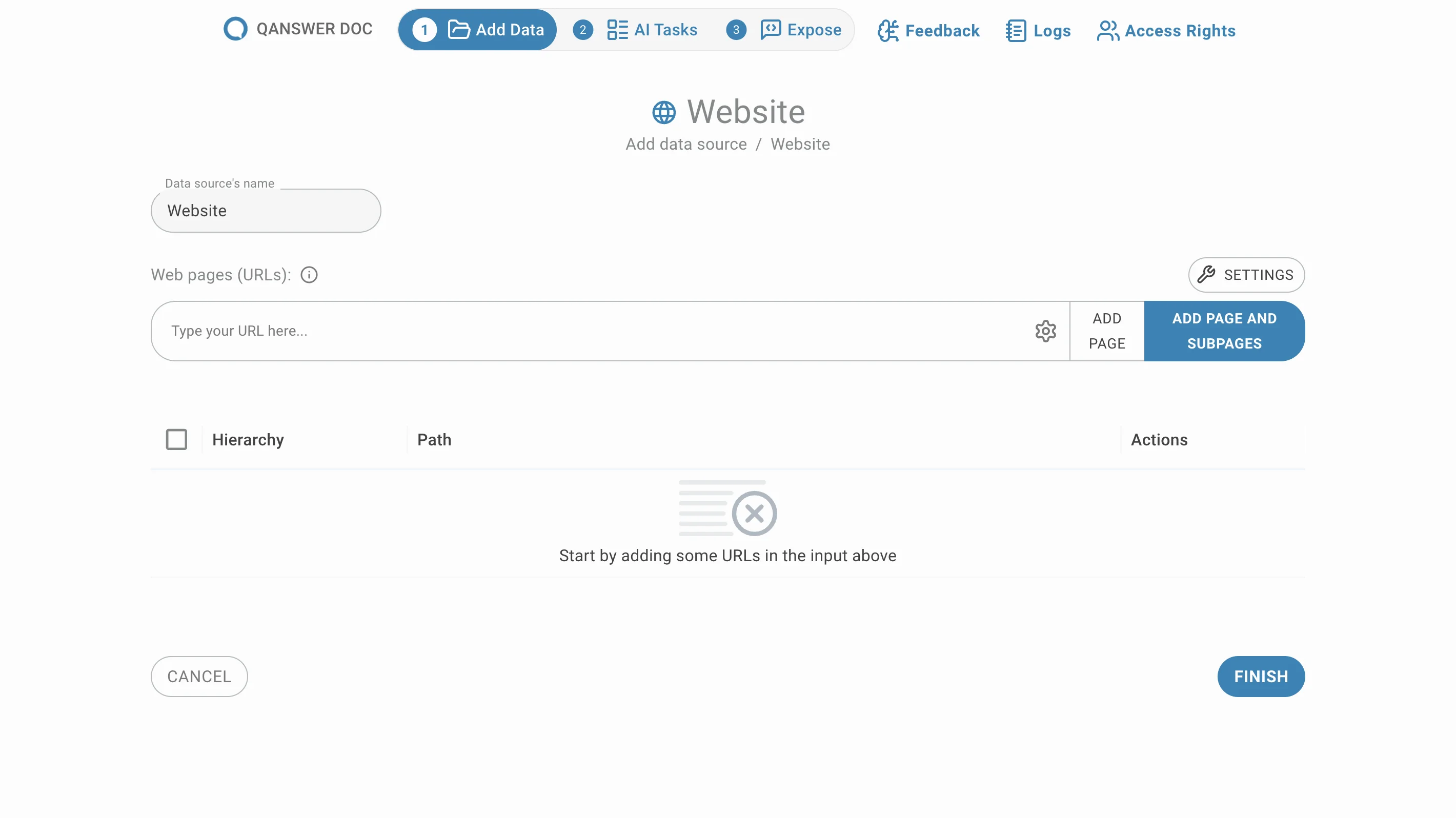
Ajouter des URLs sélectionnées manuellement
Entrez les URLs des pages que vous souhaitez ajouter et cliquez sur Ajouter une page ou appuyez sur Entrée. Vos URLs apparaîtront dans la liste ci-dessous :
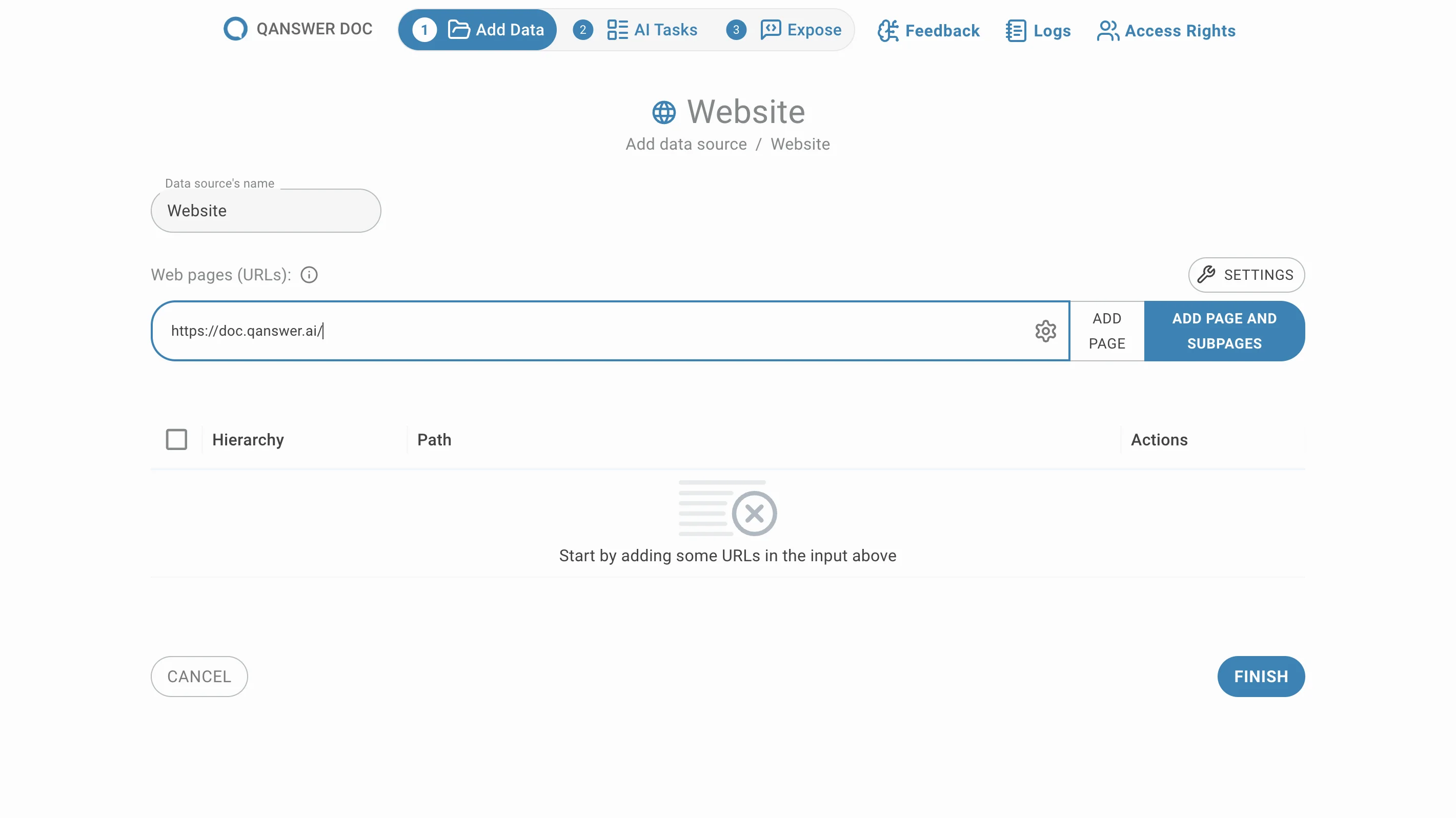
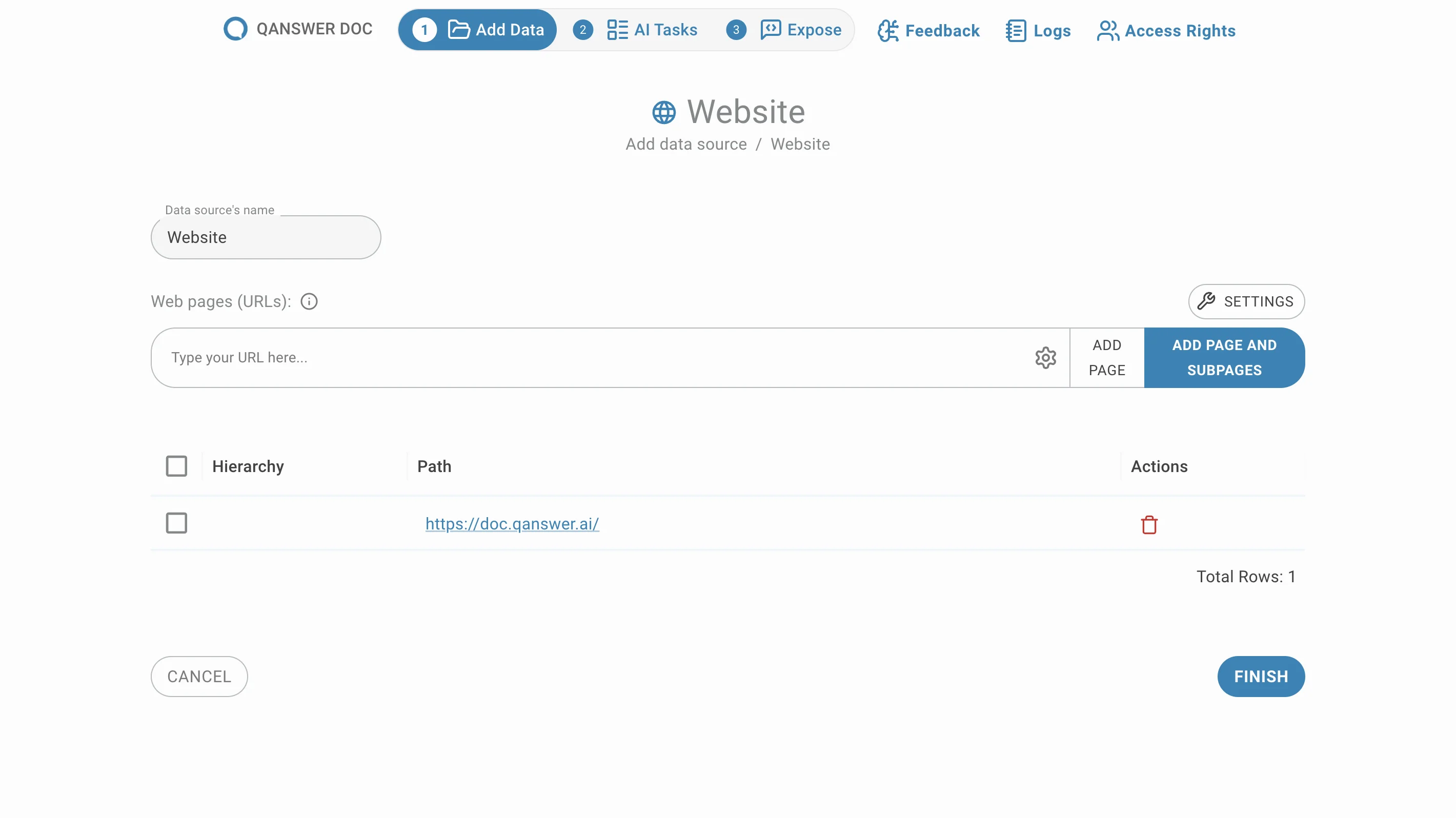
Explorer un site web entier
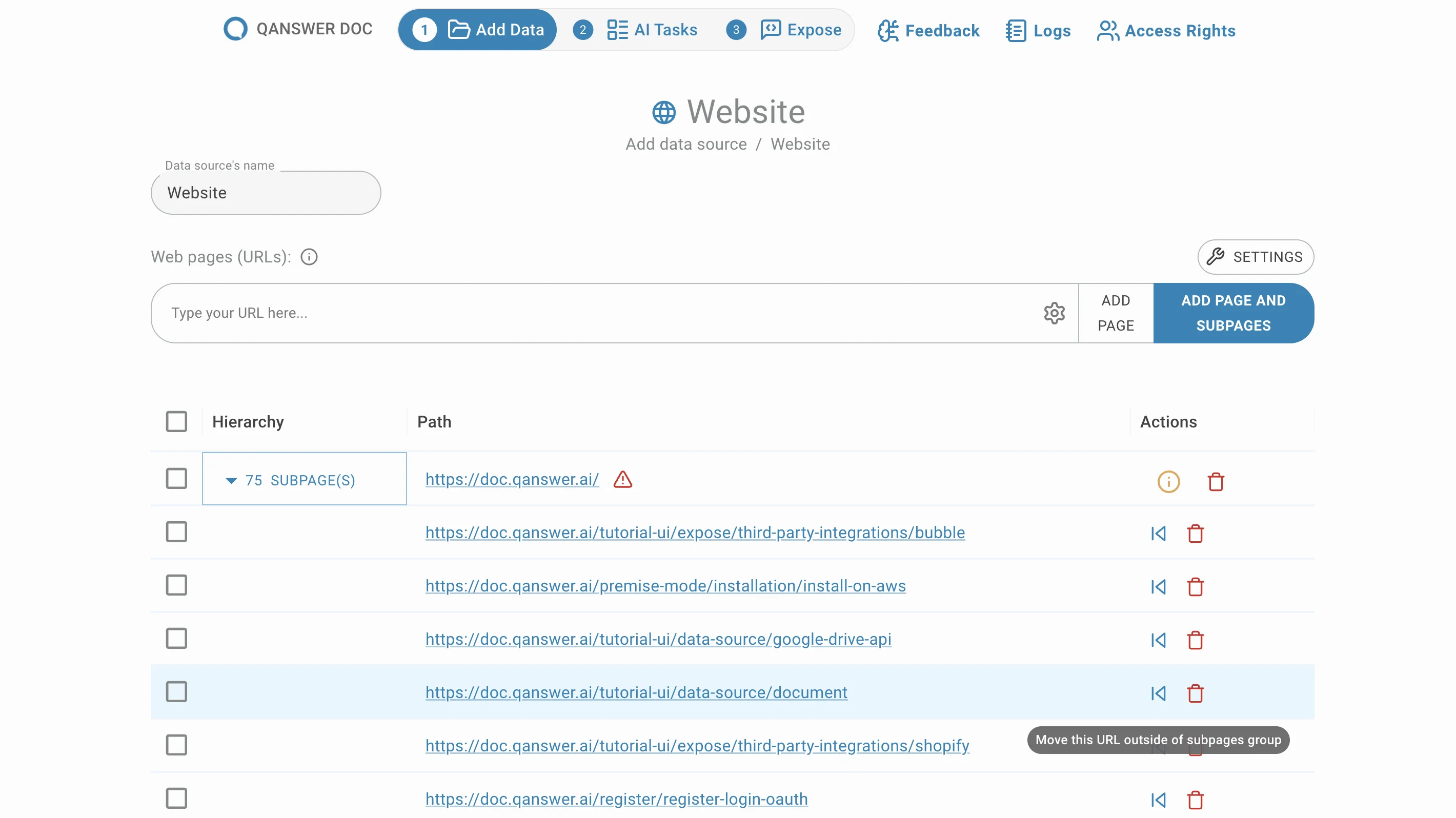
Entrez l'URL d'un site web et cliquez sur Ajouter la page et les sous-pages. Toutes les sous-pages situées sous cette URL sont extraites et répertoriées, groupées par défaut.
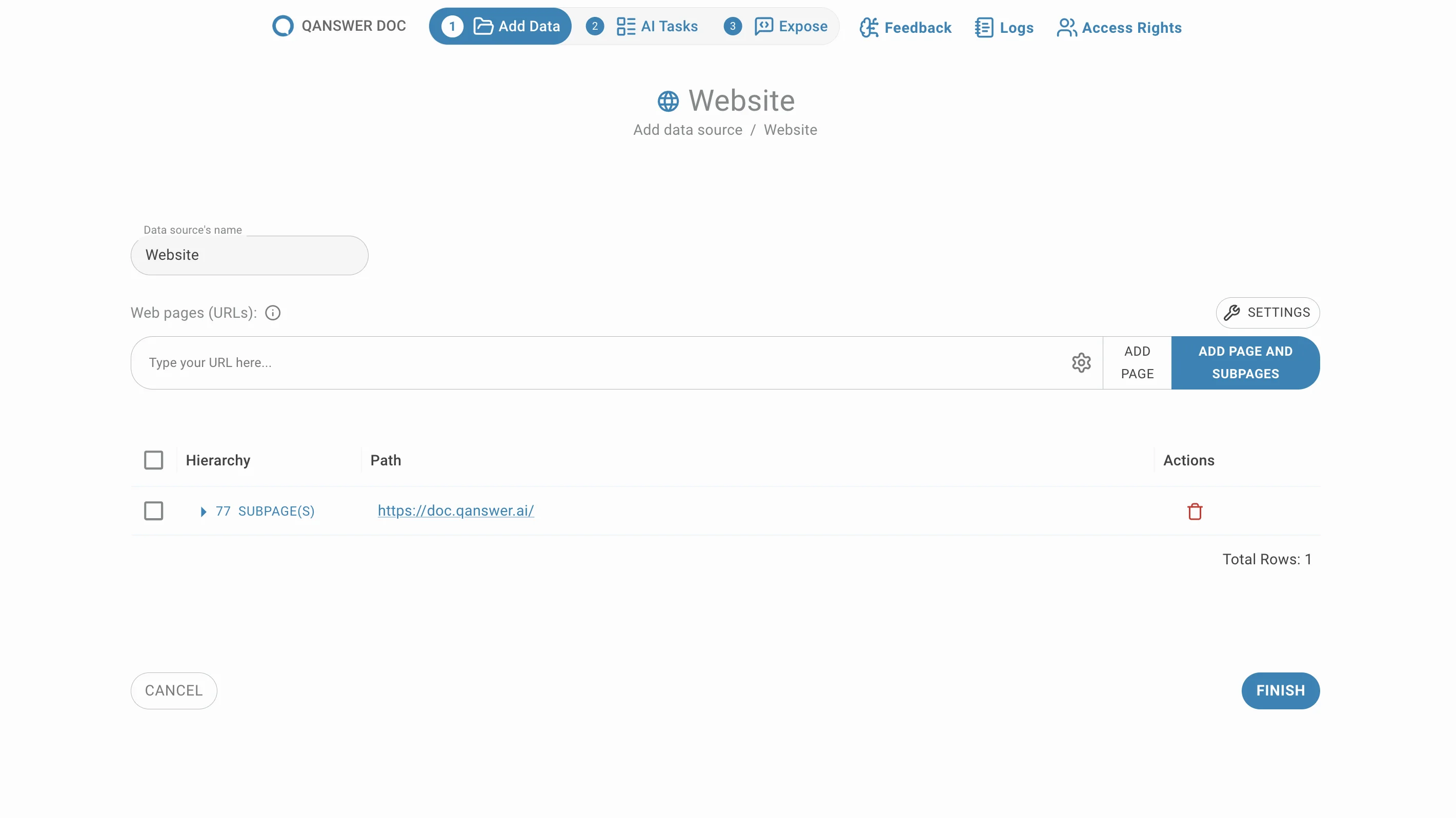
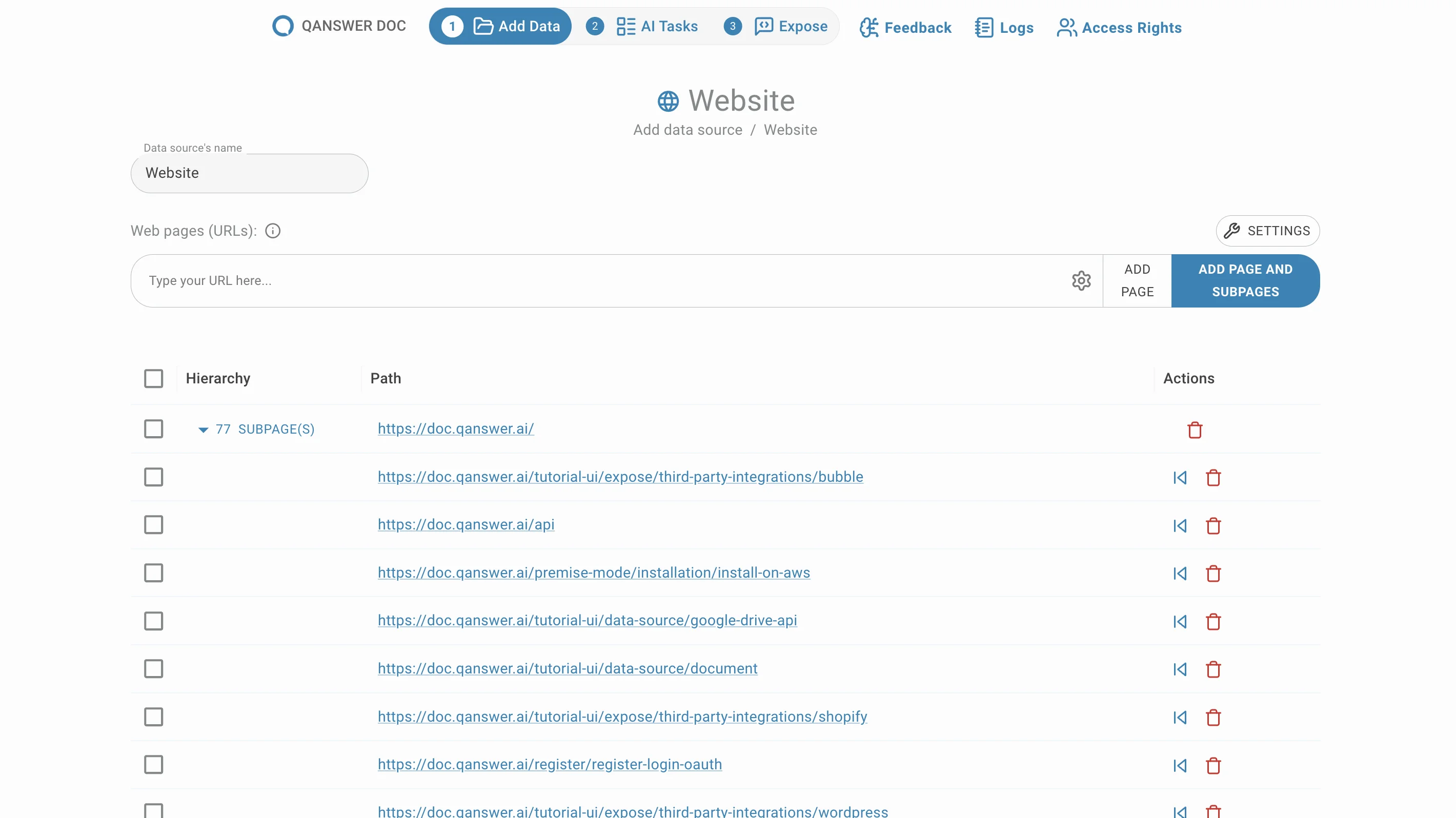
Supprimer des sous-pages
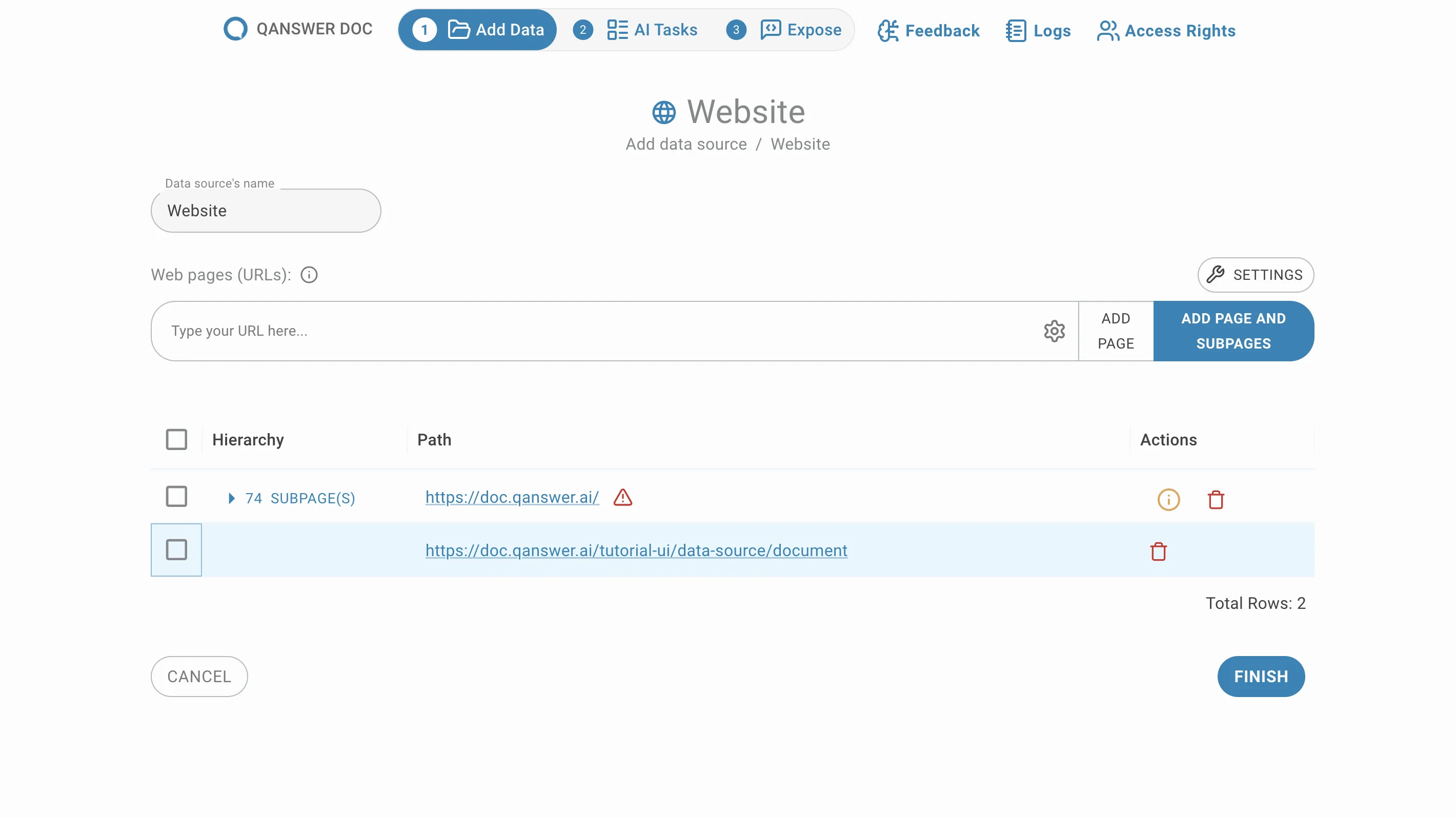
Supprimez les sous-pages indésirables en cliquant sur le bouton de suppression dans la colonne Action .
Déplacer des sous-pages
Les sous-pages sont regroupées par défaut. Déplacez-les hors de leur groupe en cliquant sur le bouton Déplacer dans la colonne Action .
Filtrage des liens ignorés
Aperçu
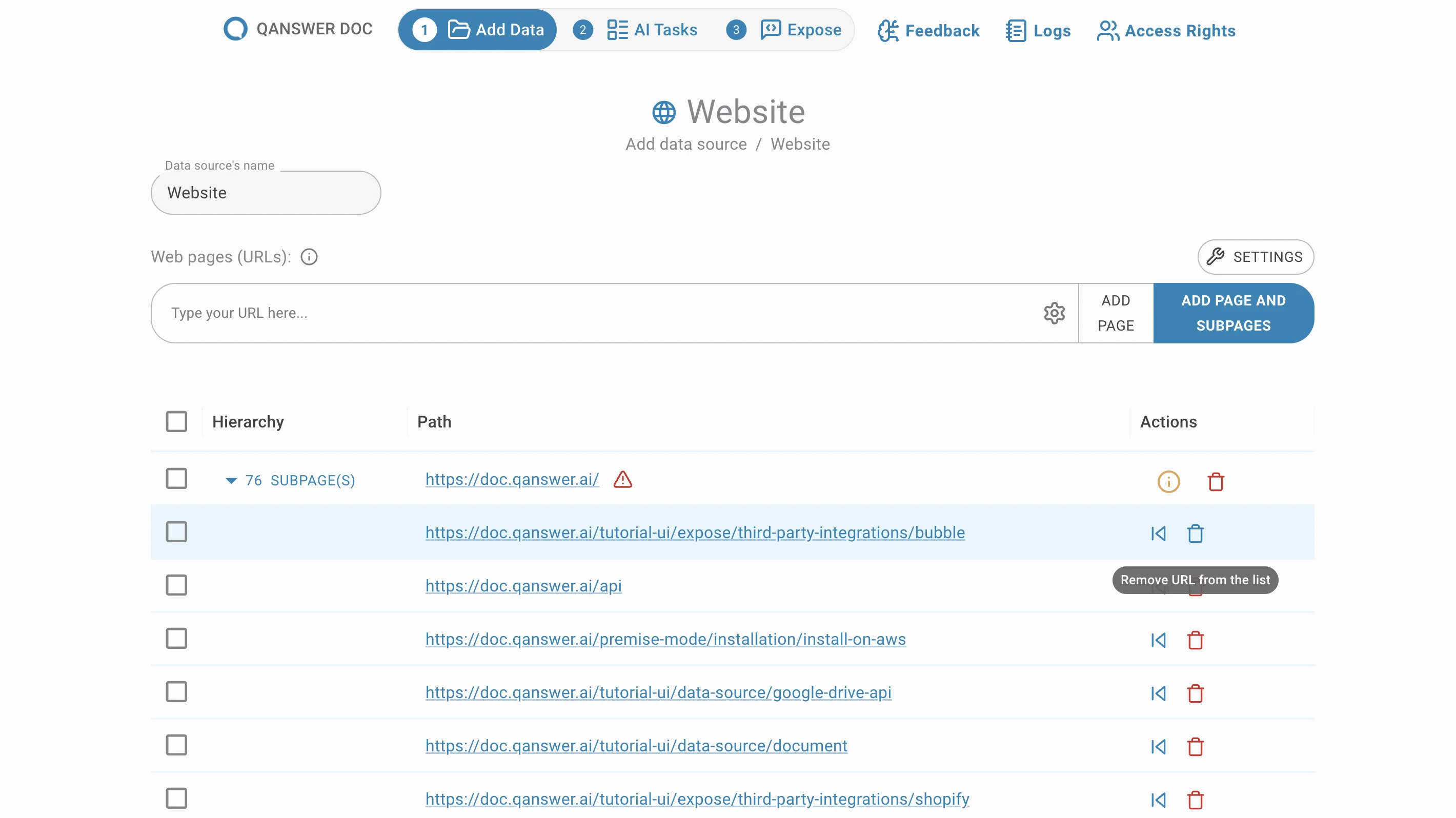
Lors de l'extraction des liens, certaines URLs peuvent être ignorées — par exemple en raison de délais d'attente ou de restrictions du site web (comme robots.txt).
Un symbole d'information peut apparaître. Par défaut, l'extraction ignore les liens qui ne contiennent pas l'URL d'origine, car ils peuvent appartenir à un site externe.
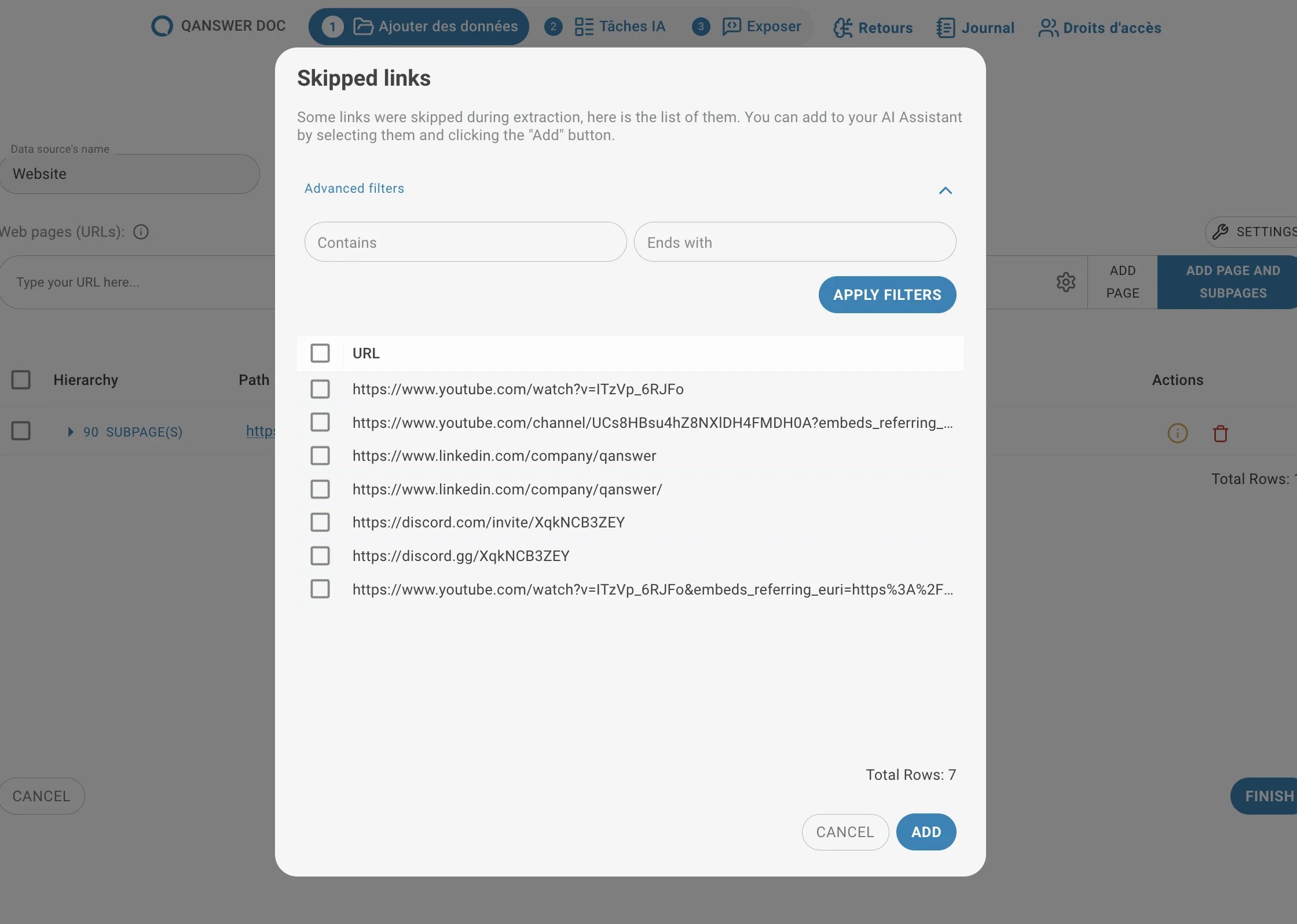
La fenêtre des liens ignorés vous permet de consulter ces URLs et de les réintégrer dans le jeu de données.
Deux filtres aident à gérer les longues listes :
- Contient
- Se termine par
Ces filtres sélectionnent des groupes d'URLs selon des modèles de texte simples.
Fonctionnement
Entrez une valeur dans l'un des filtres :
- Contient — sélectionne les URLs contenant la sous-chaîne fournie.
Exemple : Filtrer avec « /blog/ » sélectionne tous les liens ignorés sous un sous-chemin /blog/ (ex. : /blog/post-1, /blog/archive/...). - Se termine par — sélectionne les URLs se terminant par le texte fourni.
Exemple : Filtrer avec « .pdf » sélectionne tous les liens pointant vers des fichiers PDF. - Cliquez sur Appliquer les filtres.
Toutes les URLs correspondantes sont automatiquement sélectionnées.
Comportement important : sélection additive
Les sélections sont additives.
Chaque nouveau filtre ajoute les URLs correspondantes à la sélection actuelle.
Les URLs sélectionnées manuellement restent toujours sélectionnées.
Les nouveaux filtres ne suppriment jamais les URLs précédemment sélectionnées.
Exemple :
- Sélectionnez l'URL 1 manuellement.
- Appliquez un filtre correspondant à l'URL 2 et l'URL 3.
- Résultat final : les URLs 1, 2 et 3 sont sélectionnées.
Paramètres avancés (facultatif)
Personnalisez les paramètres d'exploration si nécessaire. Les valeurs par défaut conviennent à la plupart des cas d'utilisation. Les paramètres disponibles comprennent :
Détection automatique des liens (uniquement pour l'extraction des hyperliens)
- Profondeur maximale : Contrôle le nombre de niveaux en profondeur que le robot suit pour les liens. Un site web est une arborescence de pages ; ce paramètre définit jusqu'où le robot descend dans cette arborescence.
- Délai d'attente : Définit la limite de temps pour la découverte des liens. Le robot s'arrête prématurément si cette limite est atteinte.
Authentification (pour l'indexation des liens et des pages)
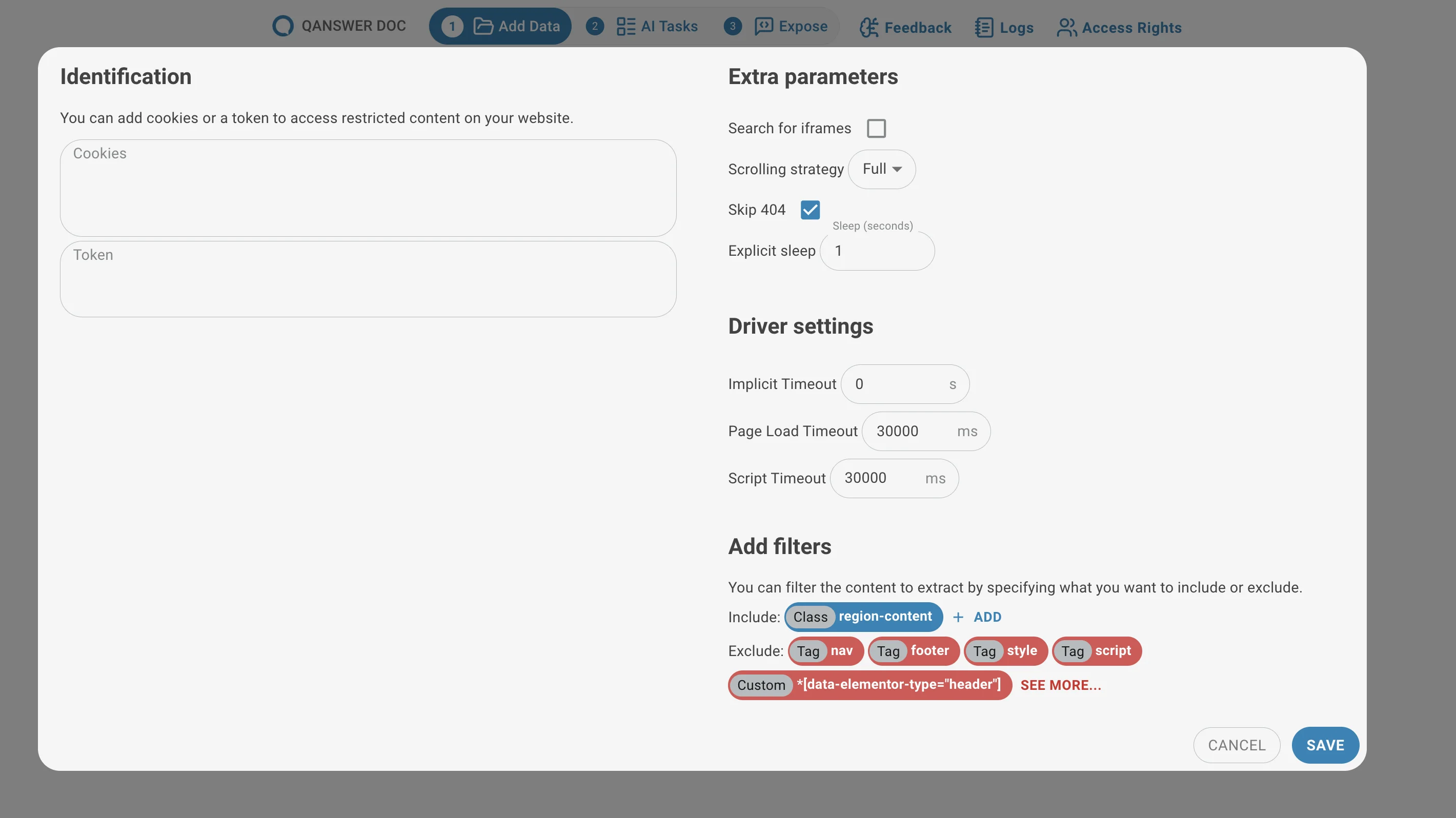
- Cookies : Certains sites web requièrent des cookies pour l'accès. Fournissez-les sous forme de dictionnaire JSON.
{ "session": "abc123", "user_id": "789xyz" } - Jeton : Certains sites web requièrent un jeton pour l'accès. Le nom et la valeur du jeton sont écrits dans le stockage local de la page, puis la page est rechargée.
{ "token_name": "Bearer your_token_here", }
Paramètres supplémentaires (pour l'extraction des liens et l'indexation des pages)
- Rechercher des iframes : Contrôle si le robot inspecte le contenu des iframes. Défini sur « auto » par défaut ; peut être forcé si nécessaire.
- Stratégie de défilement : Contrôle la façon dont le robot fait défiler la page pour déclencher le chargement différé du contenu.
- Ignorer les 404 : Lorsque cette option est activée, le robot ignore les liens brisés (erreurs 404) lors de la collecte des liens au lieu de s'arrêter.
Paramètres du pilote (pour l'extraction des liens et l'indexation des pages)
- Délai implicite : Le temps d'attente fixe avant le début de chaque tentative de chargement de page.
- Délai de chargement de page : Durée pendant laquelle le robot attend le chargement complet d'une page, y compris les images et JavaScript. L'attente s'arrête lorsque cette limite est atteinte.
- Délai d'exécution des scripts : Durée pendant laquelle le robot attend la fin de l'exécution de JavaScript avant de continuer.
Ajouter des filtres (pour l'extraction des liens et l'indexation des pages)
- Inclure : Balises HTML sur lesquelles le robot doit se concentrer lors de la collecte de liens ou de contenu (ex. :
<div>,<a>). - Exclure : Balises HTML ou sections que le robot doit ignorer (ex. :
<script>,<footer>).
Créer
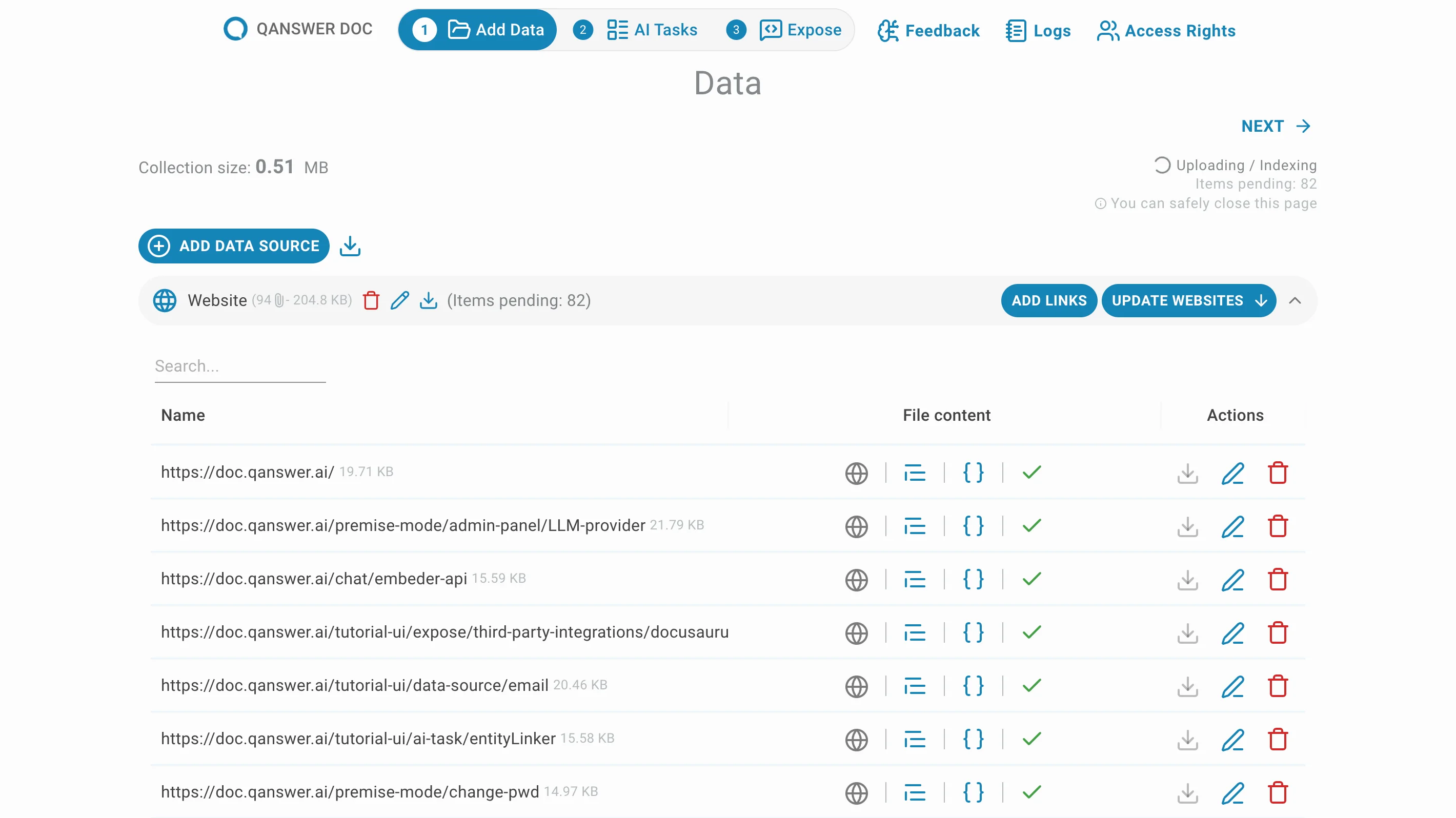
Cliquez sur Terminer pour accéder à la page de source de données. Les pages sélectionnées commencent à être explorées immédiatement.
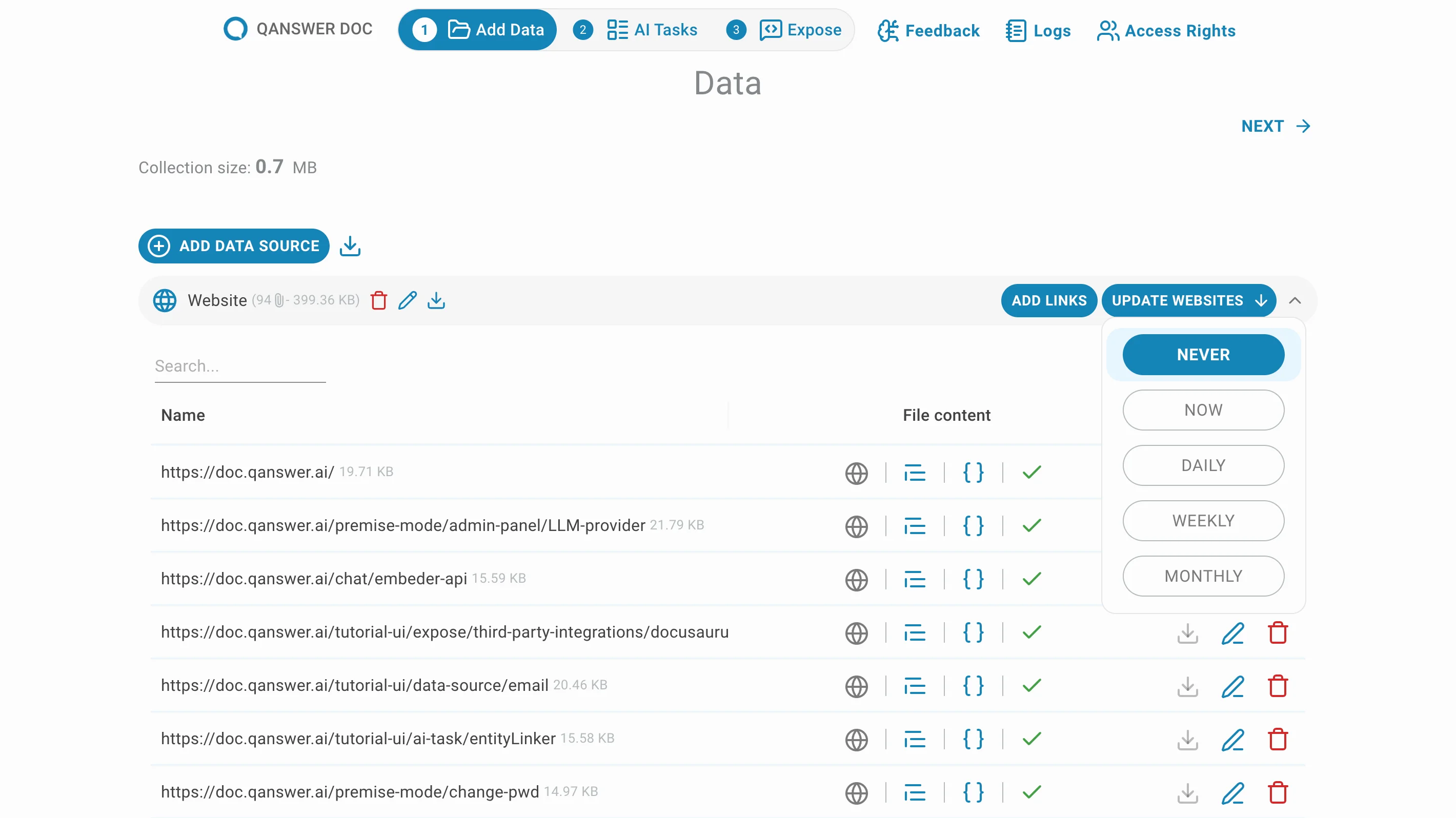
Cliquez sur Mettre à jour les sites web pour définir la fréquence des mises à jour automatiques d'exploration.
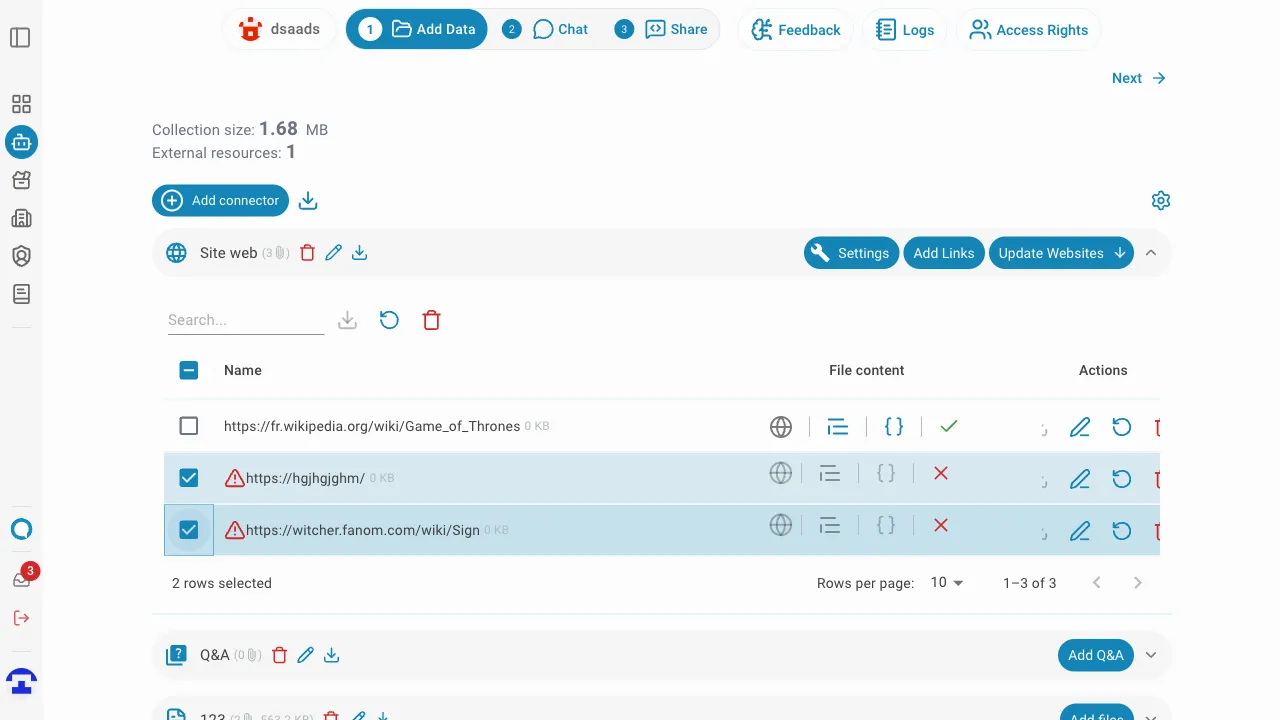
Actions groupées sur les liens sélectionnés
Vous pouvez sélectionner plusieurs liens à la fois en utilisant les cases à cocher sur le côté gauche de chaque ligne.
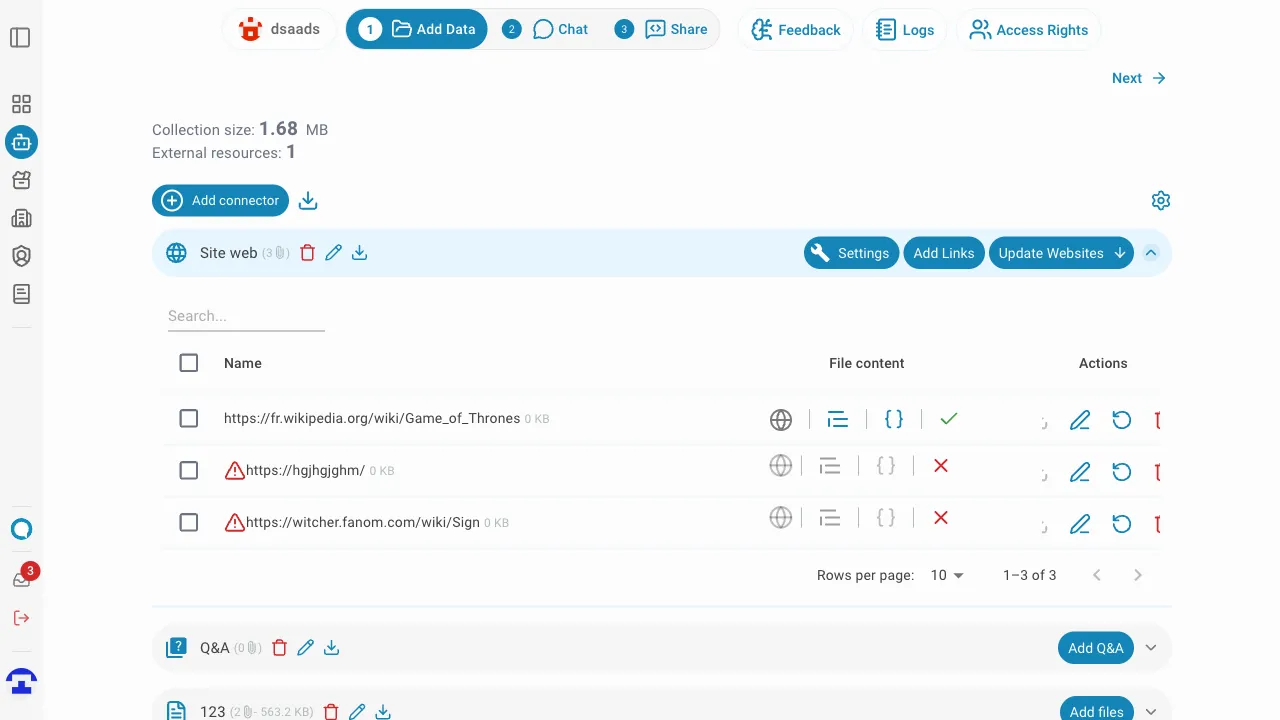
Une fois un ou plusieurs liens sélectionnés, une barre d'actions groupées apparaît au-dessus du tableau avec les actions suivantes :
- Réessayer les liens sélectionnés — réindexe tous les liens de site web sélectionnés en parallèle. Utile pour réindexer les liens qui ont précédemment échoué ou qui doivent être actualisés.
- Supprimer — supprime définitivement tous les liens sélectionnés du connecteur.