Options d'analyse des documents
La boîte de dialogue Options d'analyse contrôle la façon dont QAnswer transforme vos documents importés en un index consultable. Depuis un seul endroit, vous pouvez choisir le modèle d'embedding, régler le découpage des documents en fragments, basculer entre les pipelines d'indexation haute précision et rapide, ajuster l'invite d'indexation LLM et forcer une réindexation complète après toute modification.
Ouvrir la boîte de dialogue
Accédez à la page Ajouter des données de votre assistant et cliquez sur le bouton
La boîte de dialogue est organisée en deux onglets :
- Indexation — comment le texte est extrait de vos fichiers et comment l'assistant est retraité.
- Embedding et découpage — quel modèle d'embedding est utilisé et comment les documents sont découpés en fragments.
Onglet Indexation
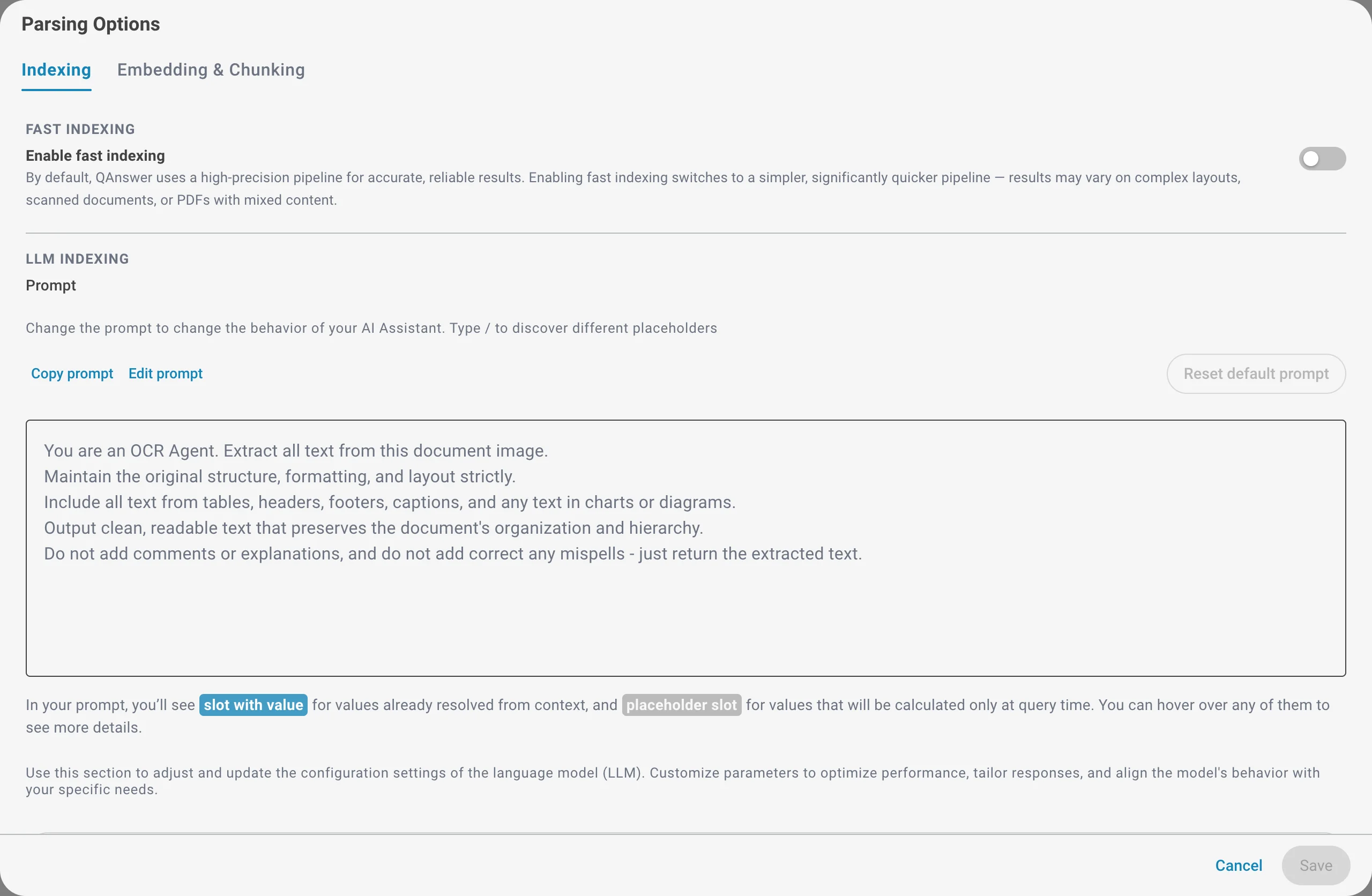
Indexation rapide
Par défaut, QAnswer utilise un pipeline haute précision pour des résultats fiables et exacts. Activer l'indexation rapide bascule vers un pipeline plus simple et nettement plus rapide. Utilisez-la pour indexer rapidement de gros volumes lorsque vos documents ont une mise en page simple.
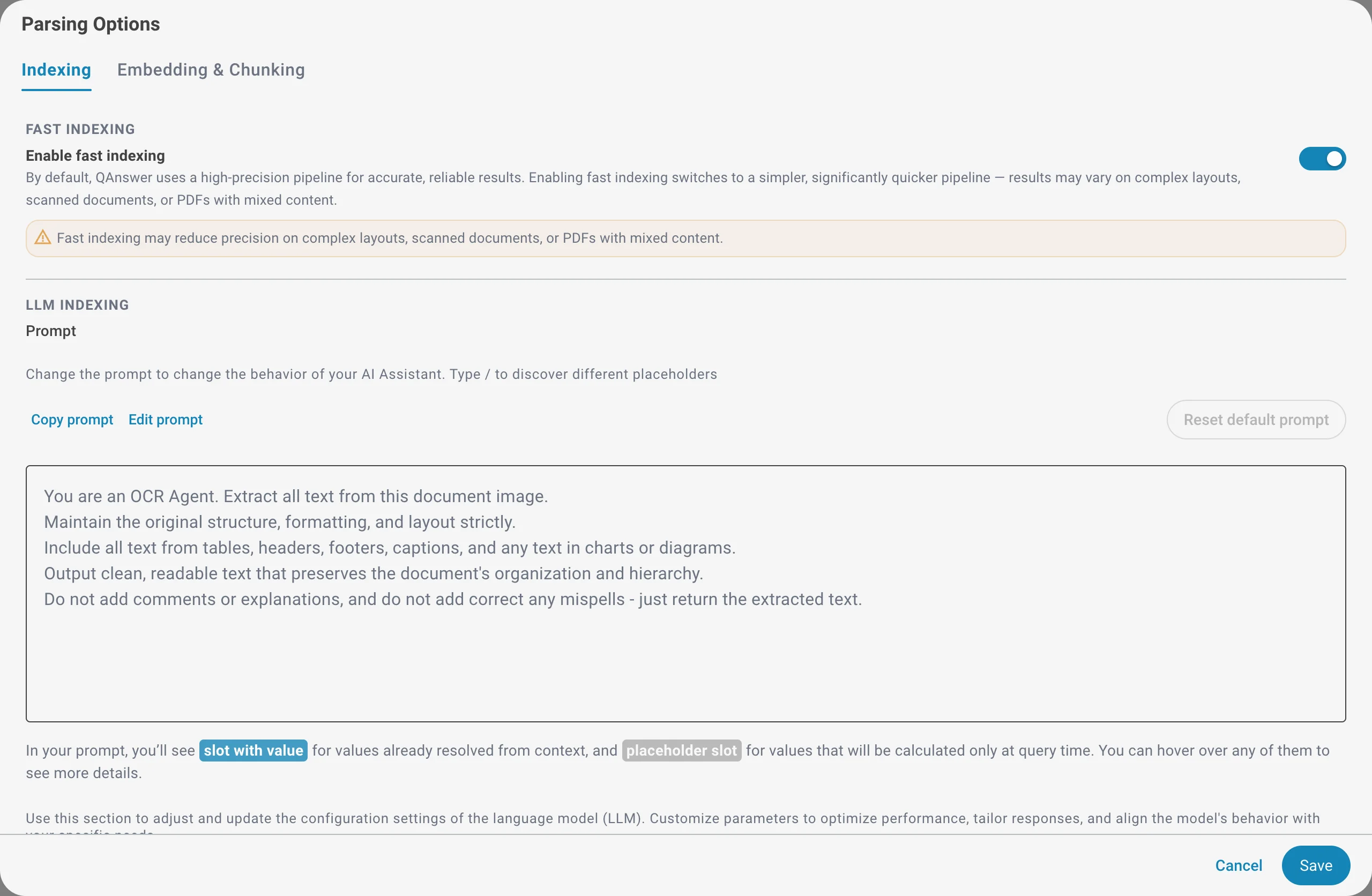
Indexation LLM
Lorsque votre offre le permet, un modèle de langage lit chaque document pendant l'indexation — particulièrement utile pour les pages numérisées et les images. Vous pouvez personnaliser l'invite d'extraction et choisir le LLM et ses paramètres (fenêtre de contexte, longueur de réponse maximale, température).
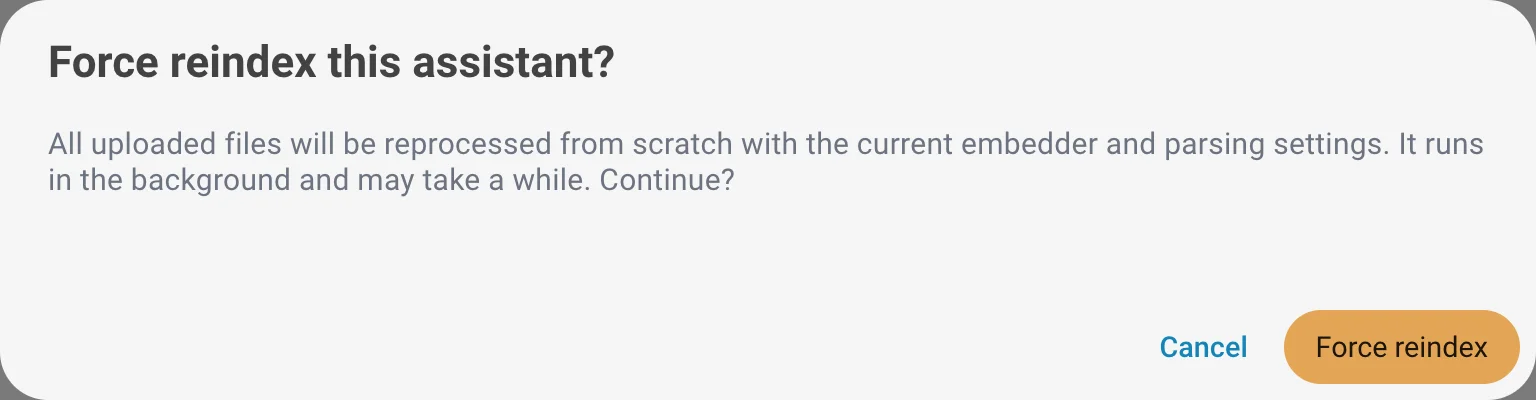
Forcer la réindexation
Retraite tous les fichiers importés dans le pipeline complet afin que l'ensemble de l'assistant soit reconstruit avec vos derniers réglages d'embedding et d'analyse. Utile après avoir changé le modèle d'embedding ou une option d'analyse, car les fichiers existants conservent les réglages avec lesquels ils ont été indexés jusqu'à leur retraitement.
Une confirmation est requise avant le démarrage de la réindexation. Elle s'exécute en arrière-plan et peut prendre du temps selon le nombre et la taille de vos fichiers.
Onglet Embedding et découpage
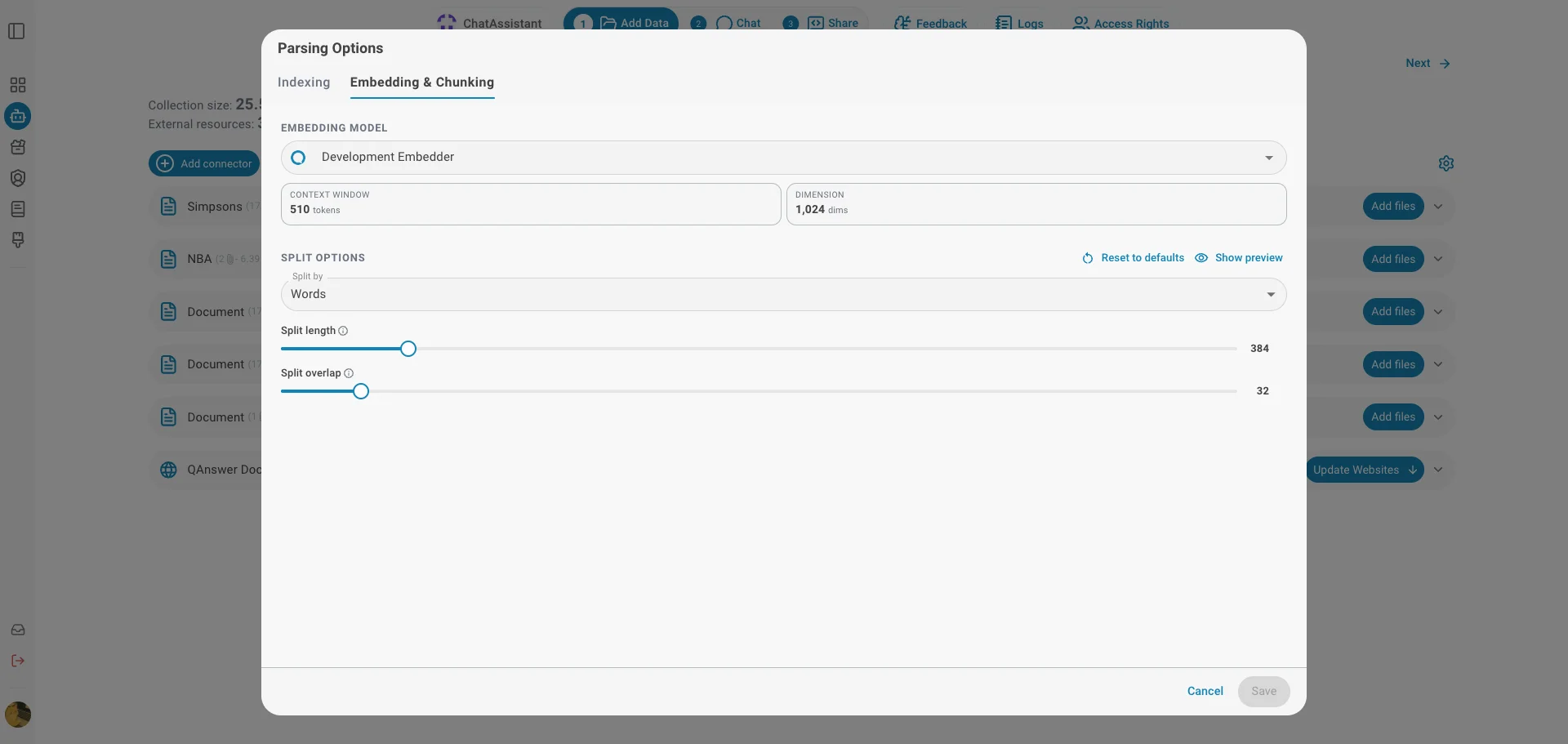
Modèle d'embedding
Choisissez le modèle d'embedding utilisé pour vectoriser vos documents. Le modèle détermine la façon dont le texte est représenté pour la recherche sémantique. Deux propriétés clés sont affichées pour le modèle sélectionné :
- Fenêtre de contexte — le nombre maximal de jetons que le modèle peut traiter à la fois. La taille de vos fragments doit rester dans cette limite.
- Dimension — la taille du vecteur en lequel chaque fragment est transformé.
Options de découpage
Les documents sont divisés en fragments plus petits avant d'être vectorisés. Ces options contrôlent la façon dont le découpage est effectué :
- Découper par — l'unité utilisée pour mesurer chaque fragment : mots, phrases ou pages.
- Longueur du fragment — le nombre d'unités contenues dans chaque fragment.
- Chevauchement — le nombre d'unités répétées entre fragments consécutifs, afin de ne pas perdre le contexte aux limites des fragments (fixé à 0 pour le découpage par page).
Utilisez Réinitialiser pour rétablir les réglages de découpage recommandés du modèle d'embedding sélectionné.
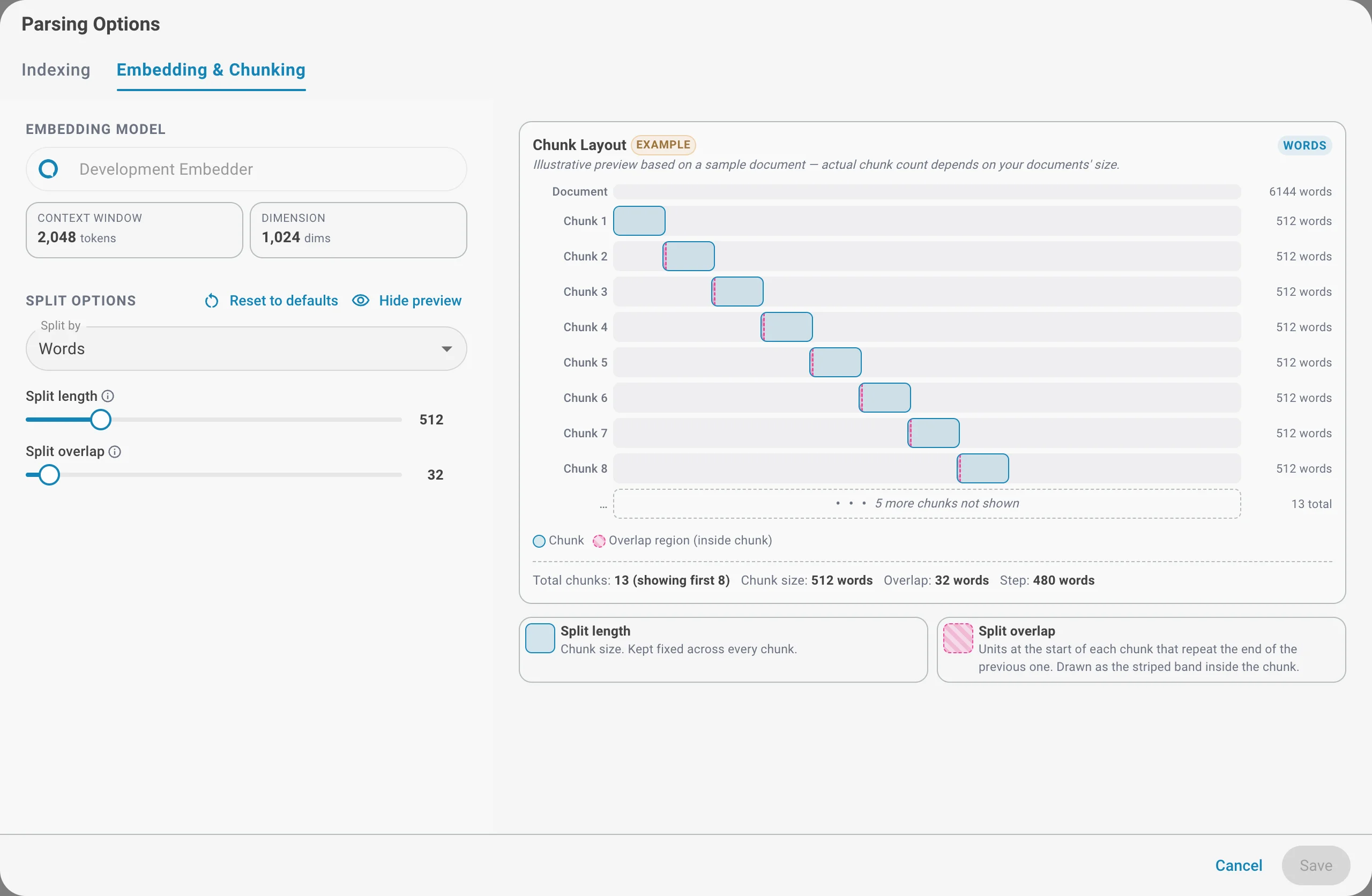
Aperçu de la disposition des fragments
Cliquez sur Afficher l'aperçu pour voir une disposition illustrative de la façon dont un document type serait découpé avec les réglages actuels — le nombre de fragments, leur taille, le chevauchement et le pas résultant entre fragments. L'aperçu n'est qu'un exemple ; le nombre réel de fragments dépend de la taille de vos documents.
Enregistrer vos modifications
Le bouton Enregistrer n'est actif que lorsqu'il y a des modifications non enregistrées. Si vous avez changé le modèle d'embedding, vous devez confirmer le changement avant d'enregistrer, car il déclenche une réindexation complète de l'assistant.