Extracteur de données
Tutoriel Vidéo
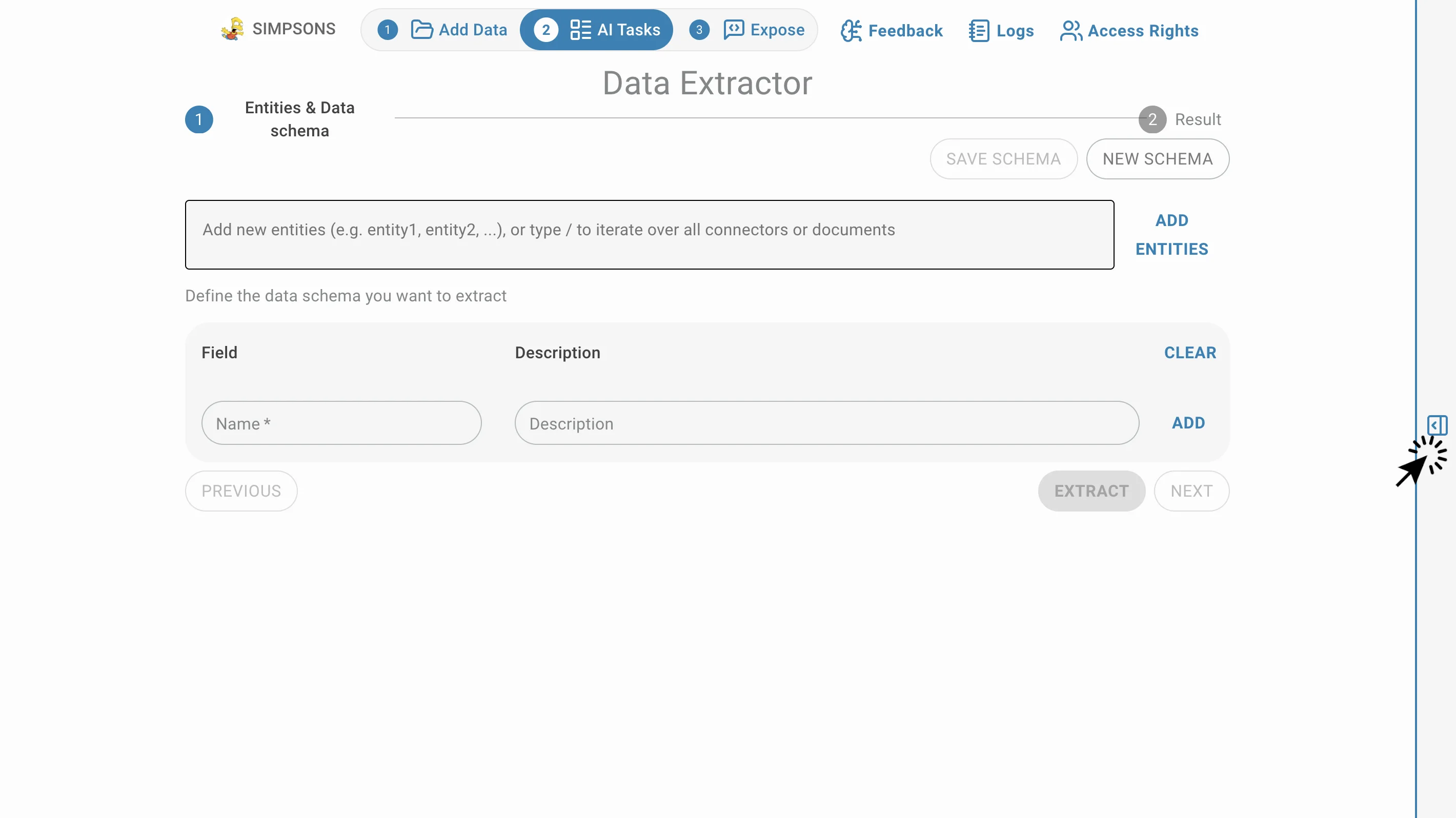
Data Extractor
Voir sur la page Tutoriels →
L'extracteur de données récupère des informations structurées à partir de documents non structurés.
Pour accéder à cette tâche IA, cliquez sur AI Tasks puis sur Data Extractor:
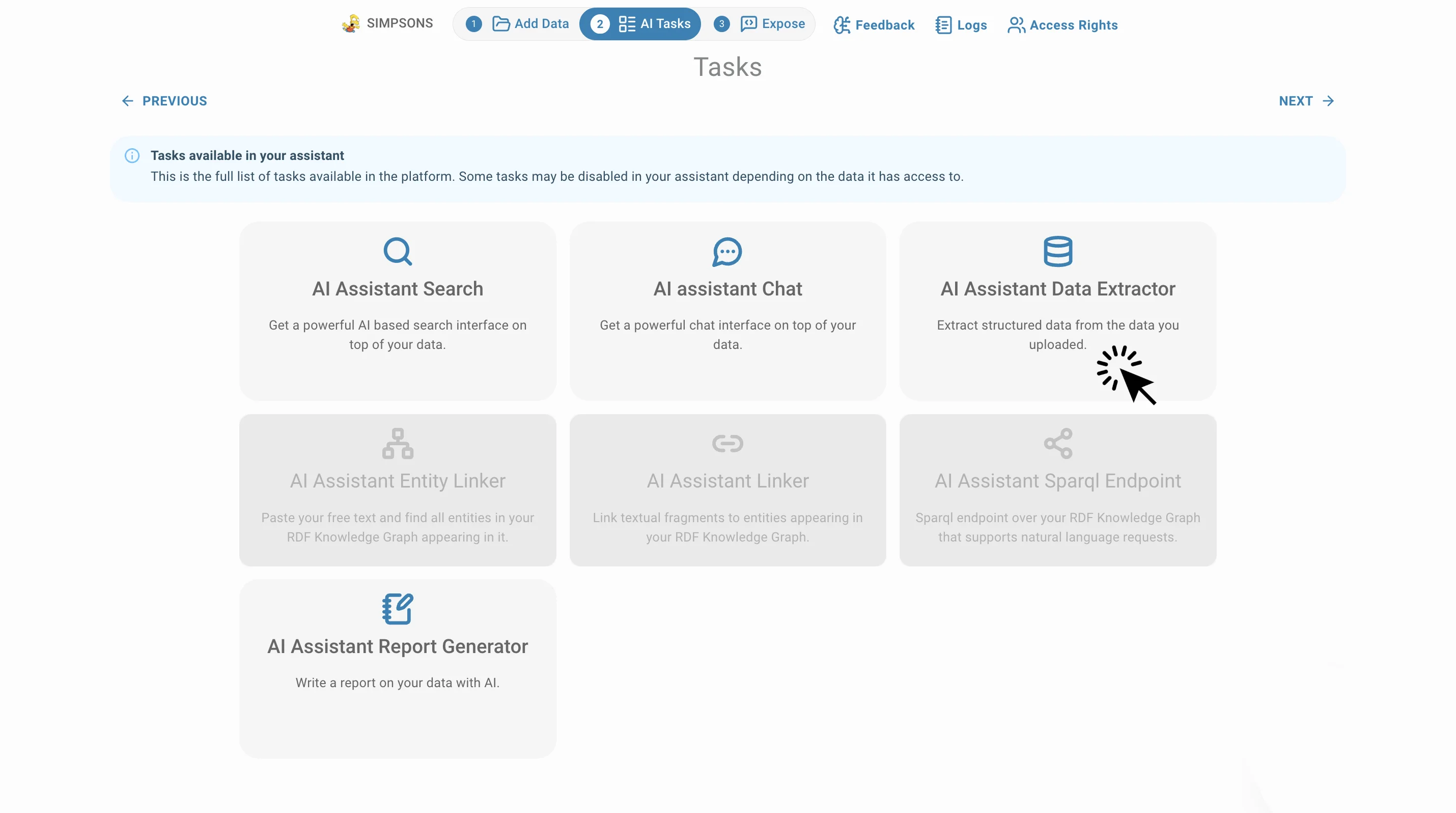
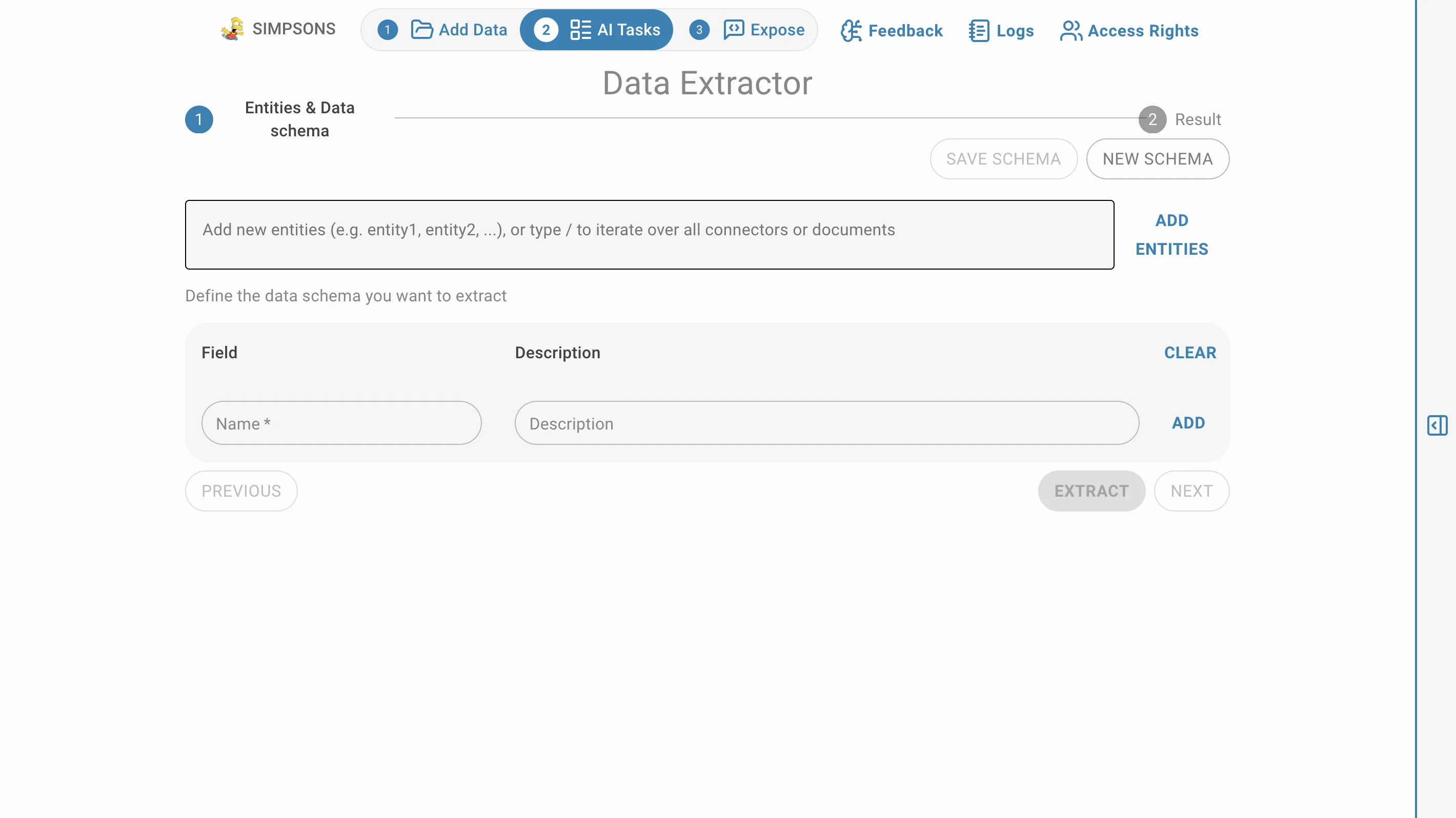
L'extracteur transforme le texte non structuré en informations structurées et exploitables.
Exemple
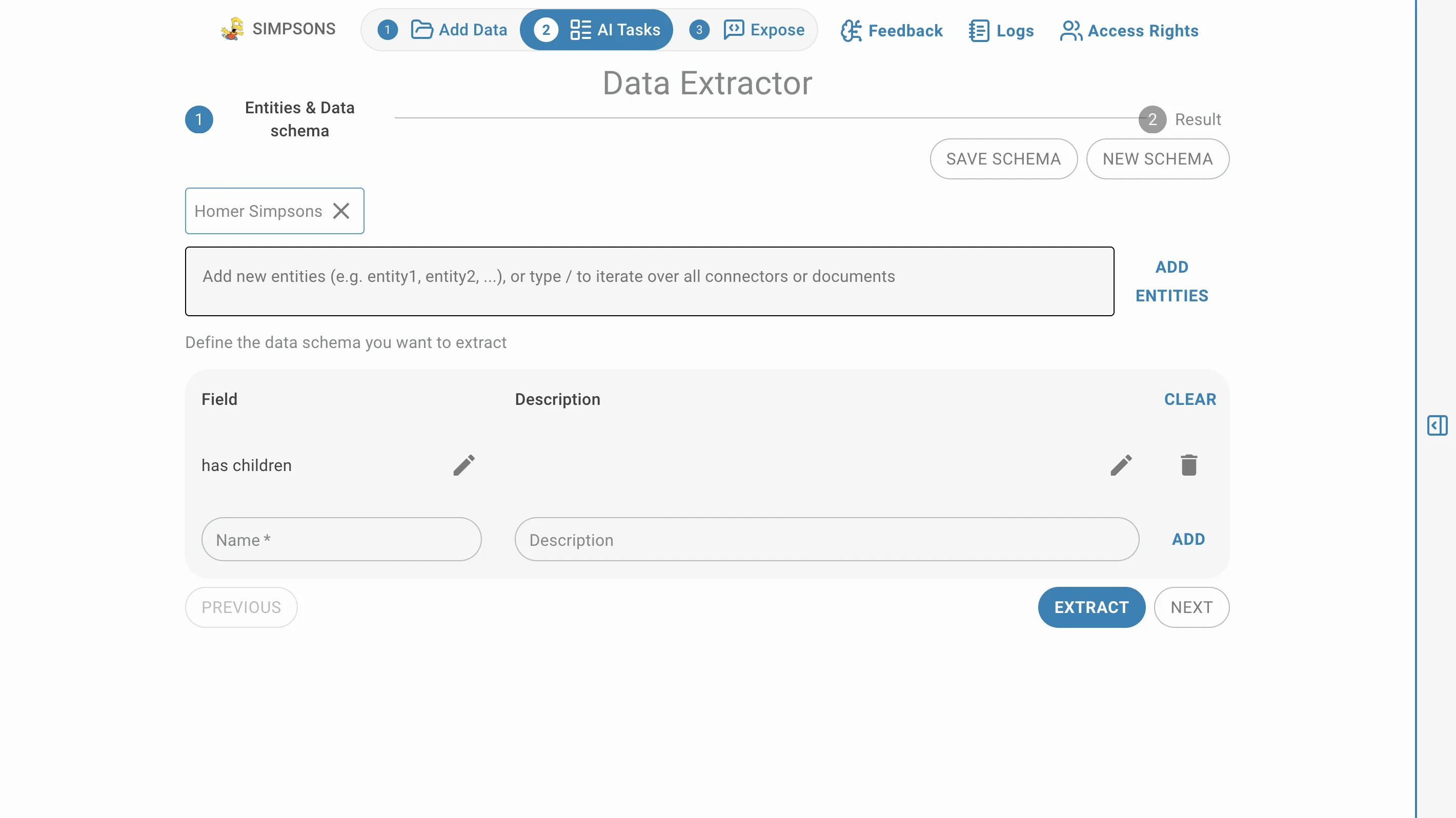
Lors de la saisie des nouvelles entités, n'oubliez pas d'appuyer sur Enter ou de cliquer sur AJOUTER DES ENTITÉS pour chaque entité. De même, lors de la saisie des schémas de données, n'oubliez pas d'appuyer sur Enter ou de cliquer sur AJOUTER pour chaque schéma.
Vous pouvez cliquer sur EFFACER pour supprimer tous les schémas saisis, les entités seront conservées.
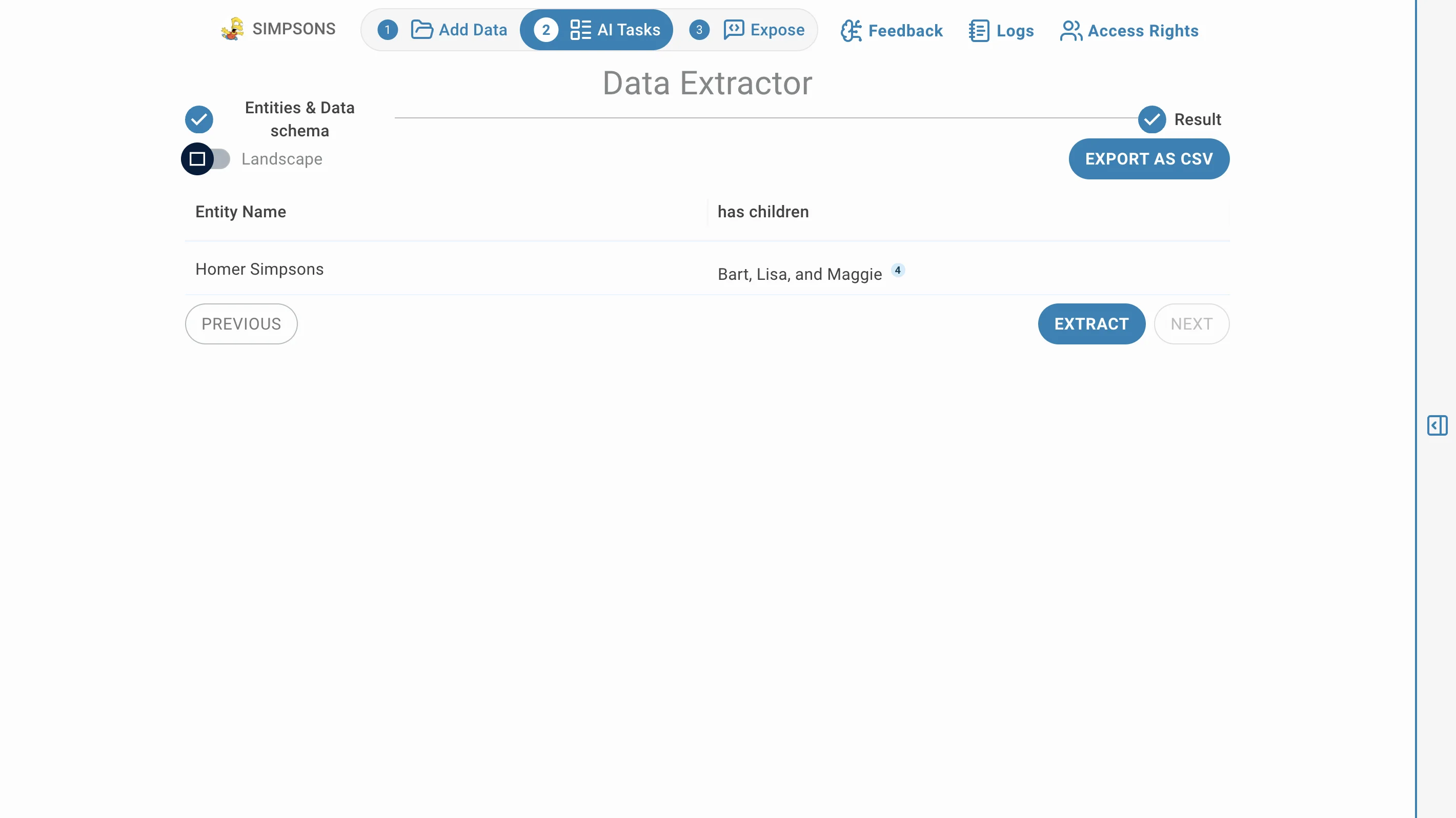
Après le processus d'extraction, vous pouvez cliquer sur EXPORTER CSV pour télécharger le format CSV du résultat d'extraction.
L'icône bleue avec un numéro représente le lien sur lequel vous pouvez cliquer pour ouvrir la source de données contenant les informations de cette extraction.
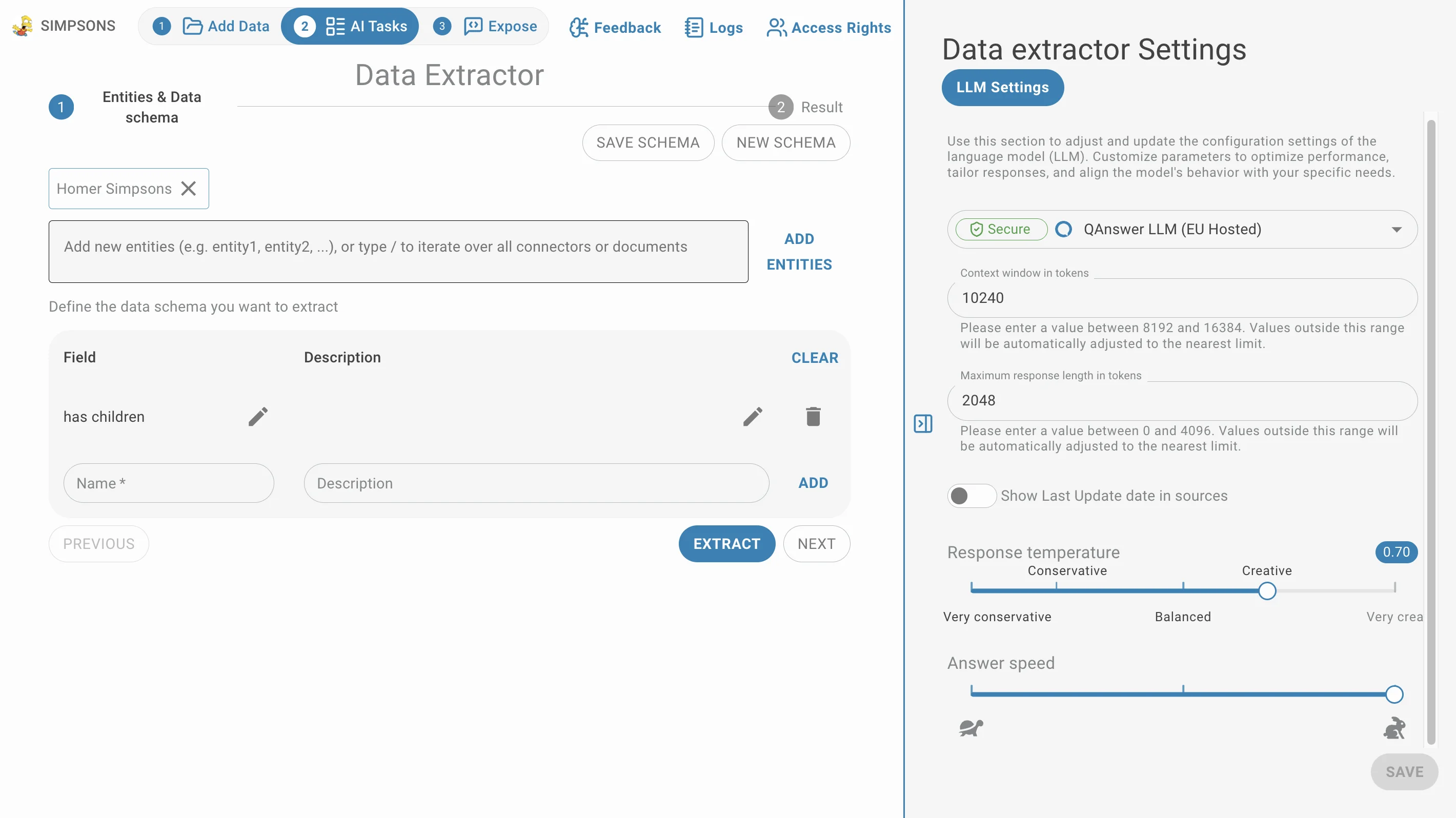
Paramètres de la tâche
Personnalisez l'assistant IA Extracteur de données en cliquant sur l'icône des paramètres :
Ajuster les paramètres du LLM: choisissez le LLM, le niveau de créativité, la vitesse de réponse, la fenêtre de contexte en tokens et la longueur maximale de réponse.
- Fenêtre de contexte (tokens) : quantité de texte (conversation + documents) que le modèle peut considérer à la fois. Si votre entrée dépasse cette limite, le contenu antérieur peut être ignoré.
- Longueur maximale de réponse : limite sur les tokens retournés par le modèle ; évite les sorties trop longues.
Conseil pratique : utilisez une température basse pour l'extraction factuelle, augmentez la fenêtre de contexte pour inclure de longs documents, et définissez une longueur de réponse maximale pour contrôler la taille de sortie et les coûts.