Audio

Tutoriel Vidéo
Audio
Voir sur la page Tutoriels →
Audio - Source de données
Utilisez un ou plusieurs fichiers audio ou enregistrements comme source de données pour votre assistant IA QAnswer. Le connecteur audio transcrit votre contenu vocal en texte indexé, vous permettant de poser des questions en langage naturel sur des réunions, des interviews, des cours, des podcasts ou tout autre contenu audio. Les téléversements de fichiers et les enregistrements en direct depuis le navigateur sont tous deux pris en charge, et plusieurs fichiers peuvent être regroupés dans un seul connecteur.
Depuis le panneau de sources de données, cliquez sur Audio pour créer un nouveau connecteur audio :
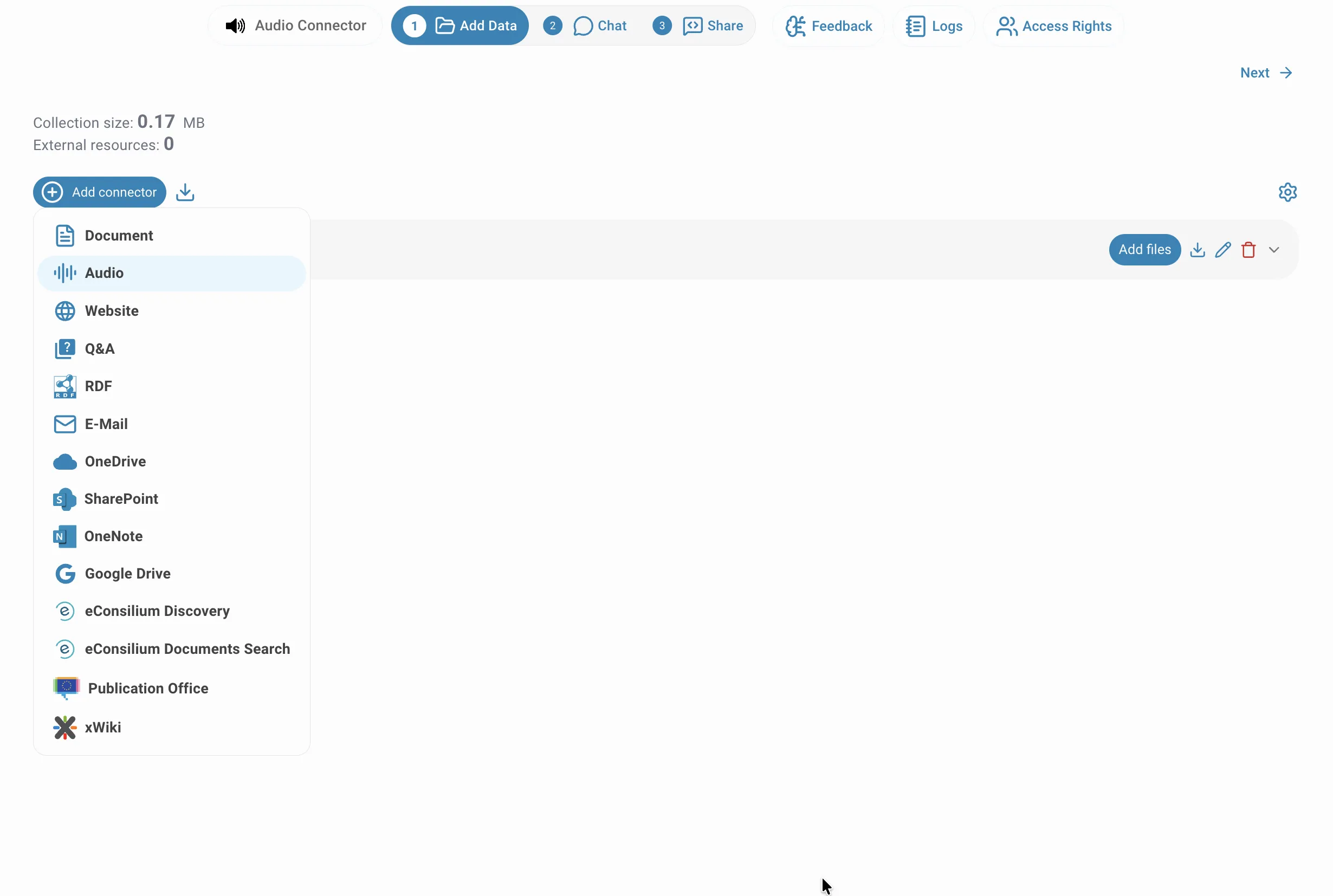
Téléverser des fichiers
Donnez un nom à votre connecteur, puis faites glisser vos fichiers audio dans la zone de dépôt — ou cliquez à l'intérieur pour ouvrir le sélecteur de fichiers. Vous pouvez ajouter plusieurs fichiers en même temps. Chaque fichier apparaît listé sous la zone de dépôt avec son nom et sa taille. Avant de cliquer sur Téléverser, vous pouvez activer la diarisation individuellement pour chaque fichier contenant plusieurs locuteurs.
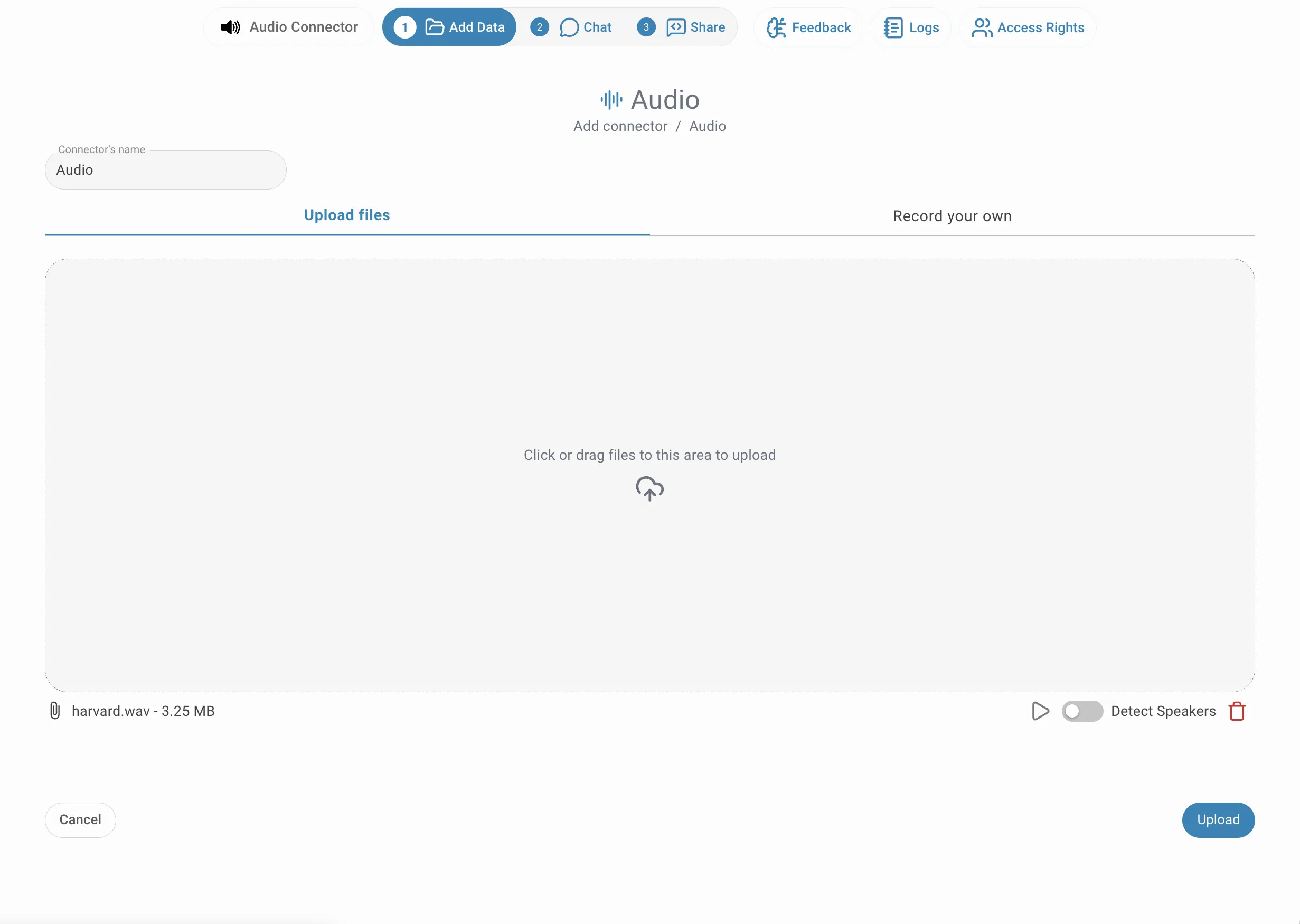
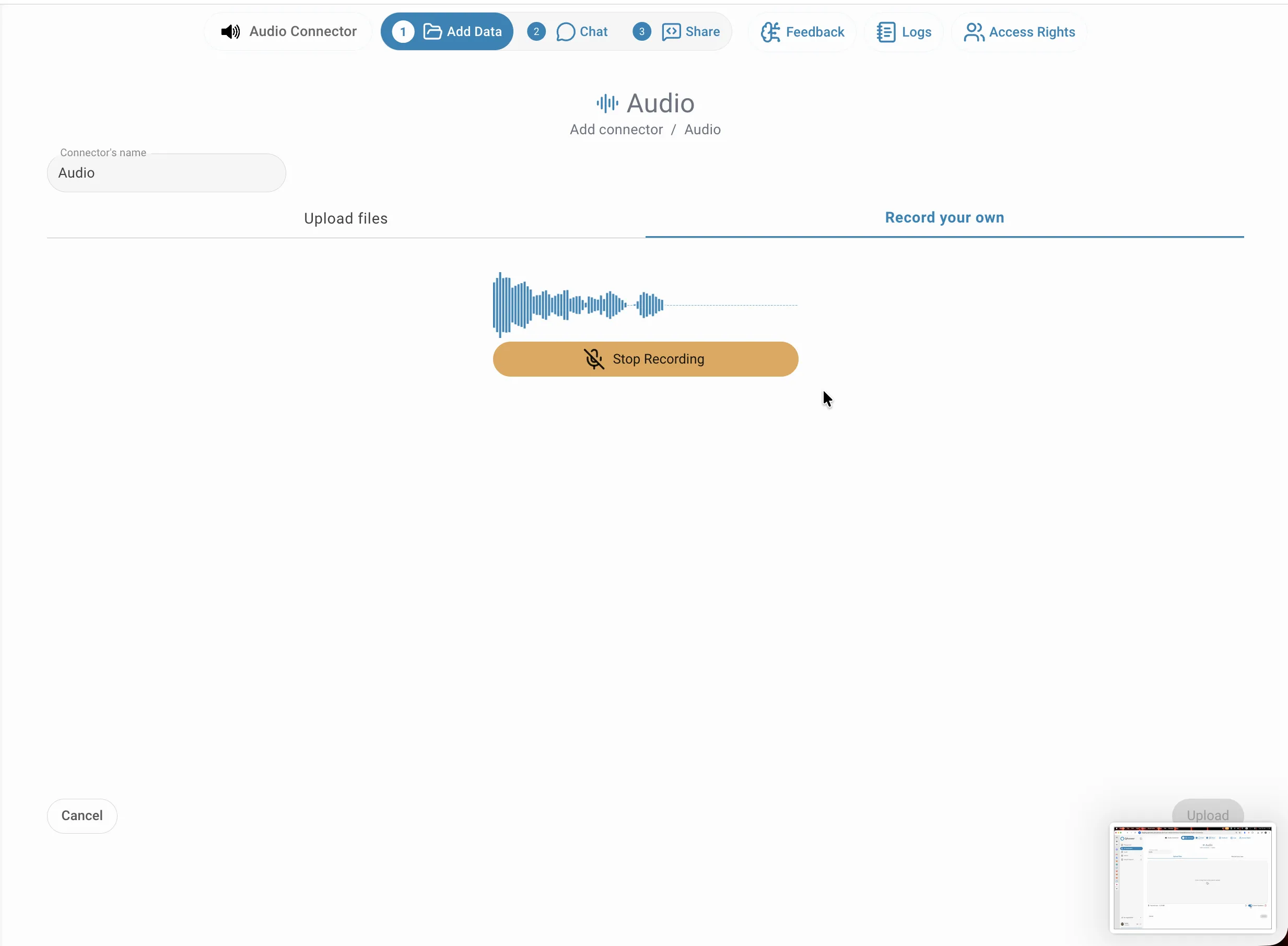
Enregistrement
Basculez vers l'onglet Enregistrer et cliquez sur Démarrer l'enregistrement pour capturer de l'audio directement dans le navigateur via votre microphone. Une forme d'onde en temps réel confirme que l'enregistrement est actif. Lorsque vous avez terminé, cliquez sur Arrêter l'enregistrement — l'audio capturé est sauvegardé et traité exactement comme un fichier téléversé. Cette option est utile pour capturer des réunions en direct, des notes vocales ou des interviews sans avoir à enregistrer un fichier au préalable.
Diarisation (Détection des locuteurs)
Pour activer la diarisation sur un fichier, cliquez sur le bouton Détecter les locuteurs à droite de la ligne de ce fichier. Le bouton peut être configuré indépendamment pour chaque fichier, ce qui vous permet de mélanger transcription simple et diarisation au sein du même connecteur selon que chaque enregistrement contient un ou plusieurs locuteurs.
La diarisation identifie automatiquement qui parle à chaque instant et divise l'audio en segments étiquetés. Les locuteurs se voient d'abord attribuer des labels génériques tels que SPEAKER_00, SPEAKER_01, etc. — vous pouvez les renommer avec des noms significatifs une fois le fichier indexé. Utilisez la diarisation pour les interviews, les tables rondes ou tout enregistrement où il est important de savoir qui a dit quoi pour vos requêtes.
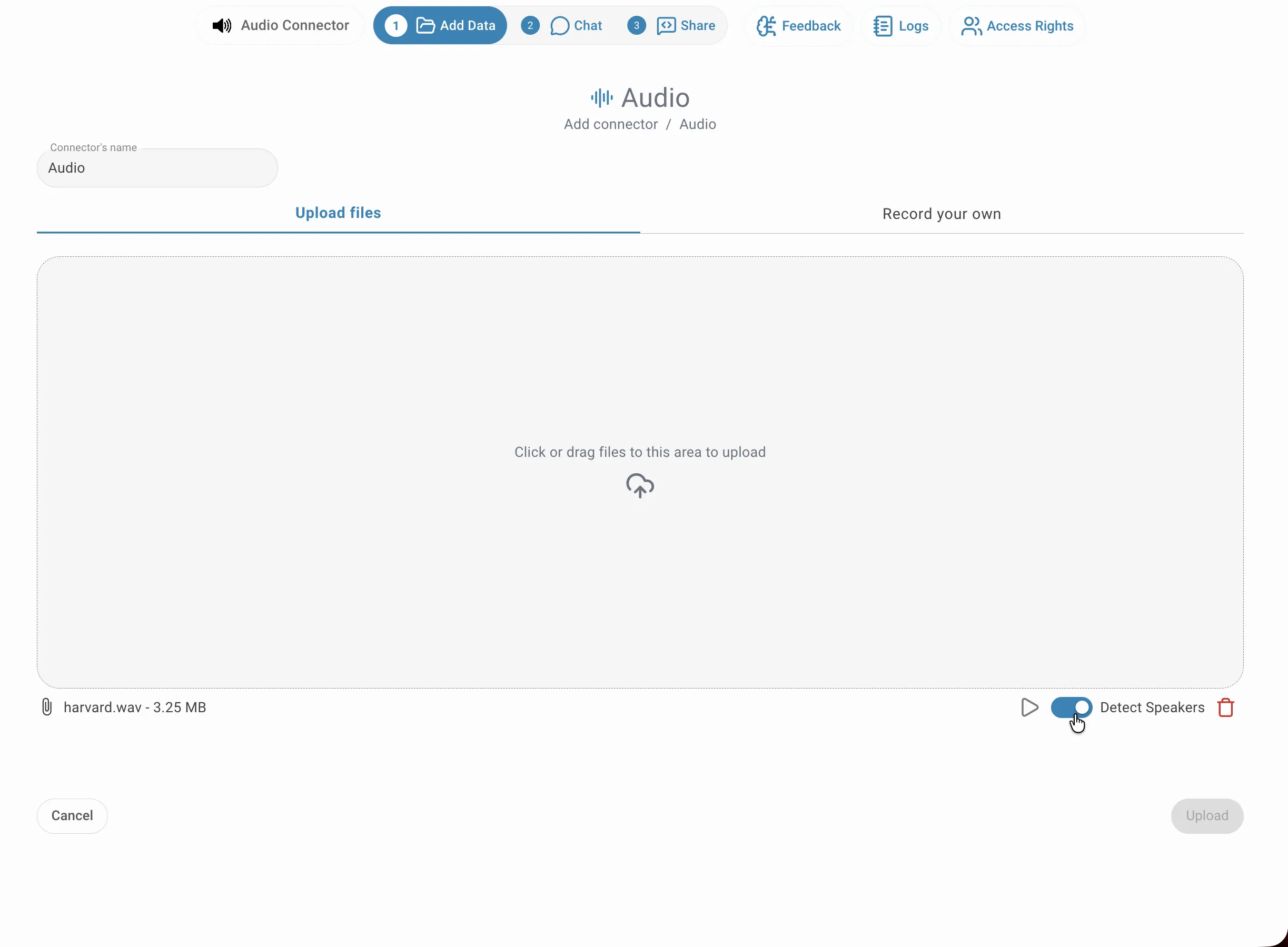
Une fois vos fichiers préparés et les préférences de diarisation configurées, cliquez sur Téléverser en bas à droite. Les fichiers sont envoyés au serveur immédiatement et la transcription s'effectue en arrière-plan — vous pouvez naviguer ailleurs ou continuer à travailler sur d'autres tâches sans attendre. Quitter la page ne fait pas perdre de progression.
Attente de l'indexation
Après le téléversement, les fichiers apparaissent dans la liste du connecteur et sont traités de manière asynchrone. La colonne de statut se met à jour au fur et à mesure que chaque fichier avance dans le pipeline de transcription. Une coche verte signifie que le fichier a été entièrement transcrit et indexé et est prêt à être interrogé. Si un fichier échoue, un indicateur d'erreur apparaît — survolez-le pour lire la raison. Vous pouvez ajouter d'autres fichiers à un connecteur existant à tout moment en cliquant sur Ajouter des fichiers sur la ligne du connecteur.
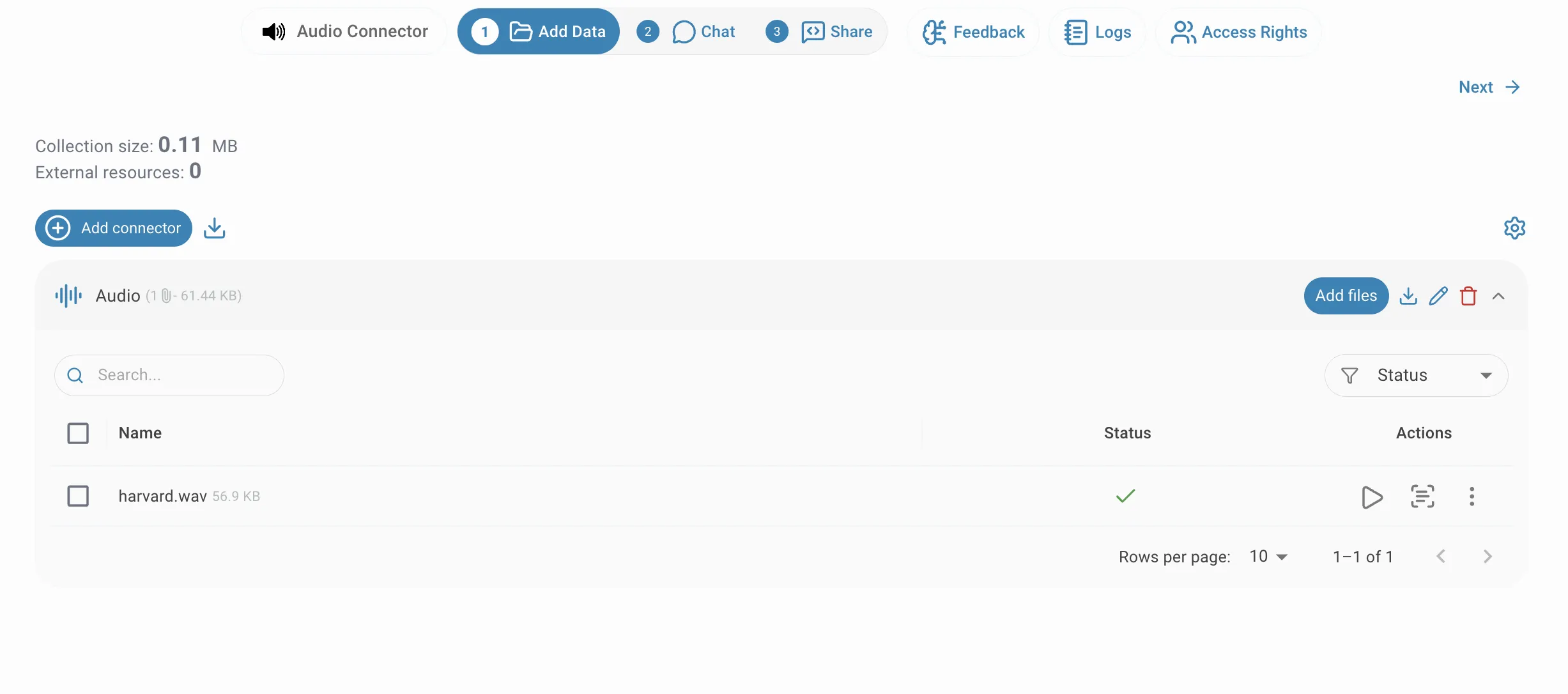
Consulter la transcription
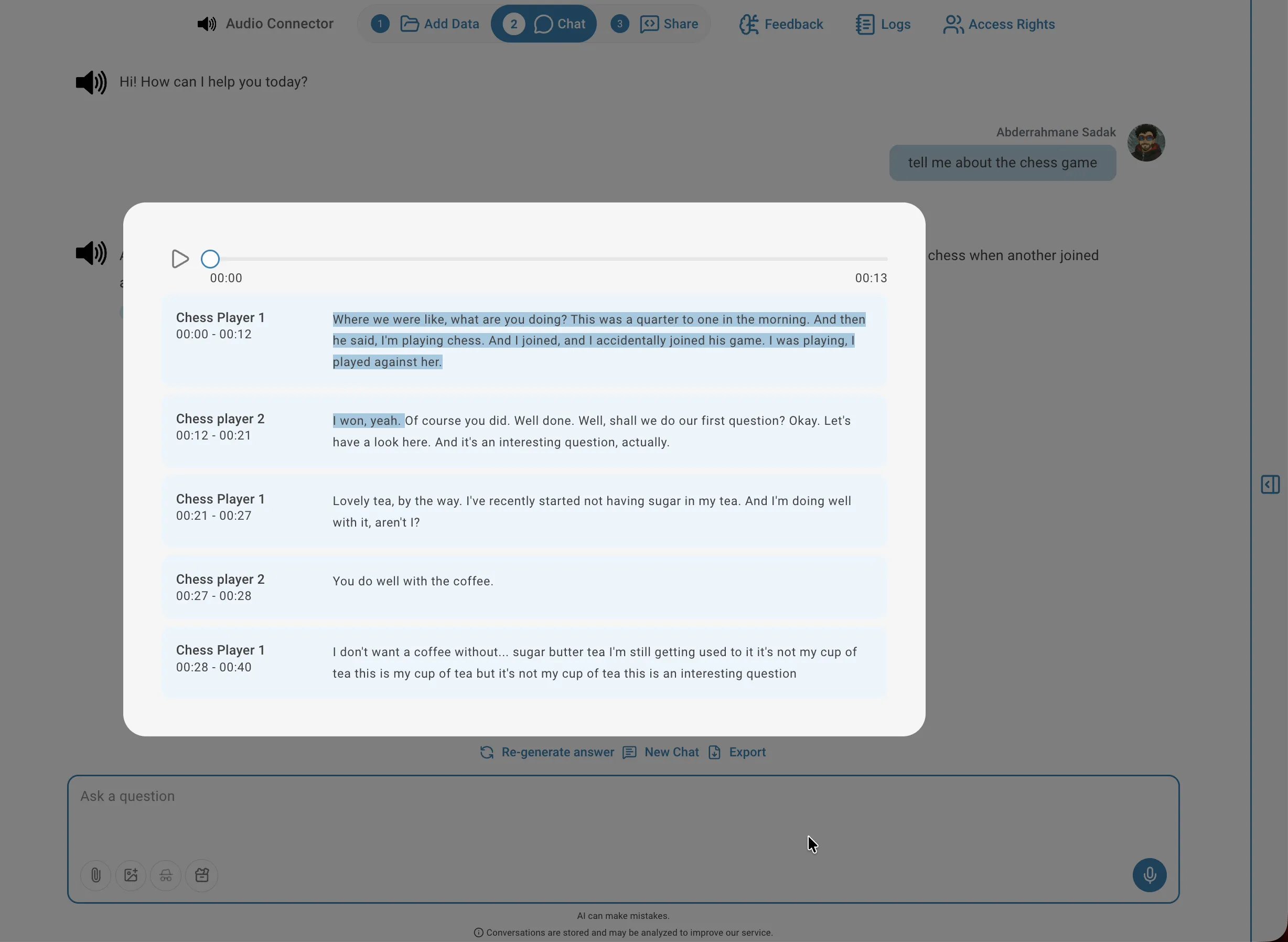
Pour consulter le résultat de transcription d'un fichier, cliquez sur l'icône de transcription dans sa ligne de la liste du connecteur. Le lecteur affiche le texte complet organisé en segments, chacun avec un label de locuteur (pour l'audio diarisé), une plage horaire et le texte transcrit. Vous pouvez écouter l'audio depuis n'importe quel segment en cliquant sur l'icône de lecture à côté, ce qui est utile pour vérifier la précision ou contrôler le contexte.
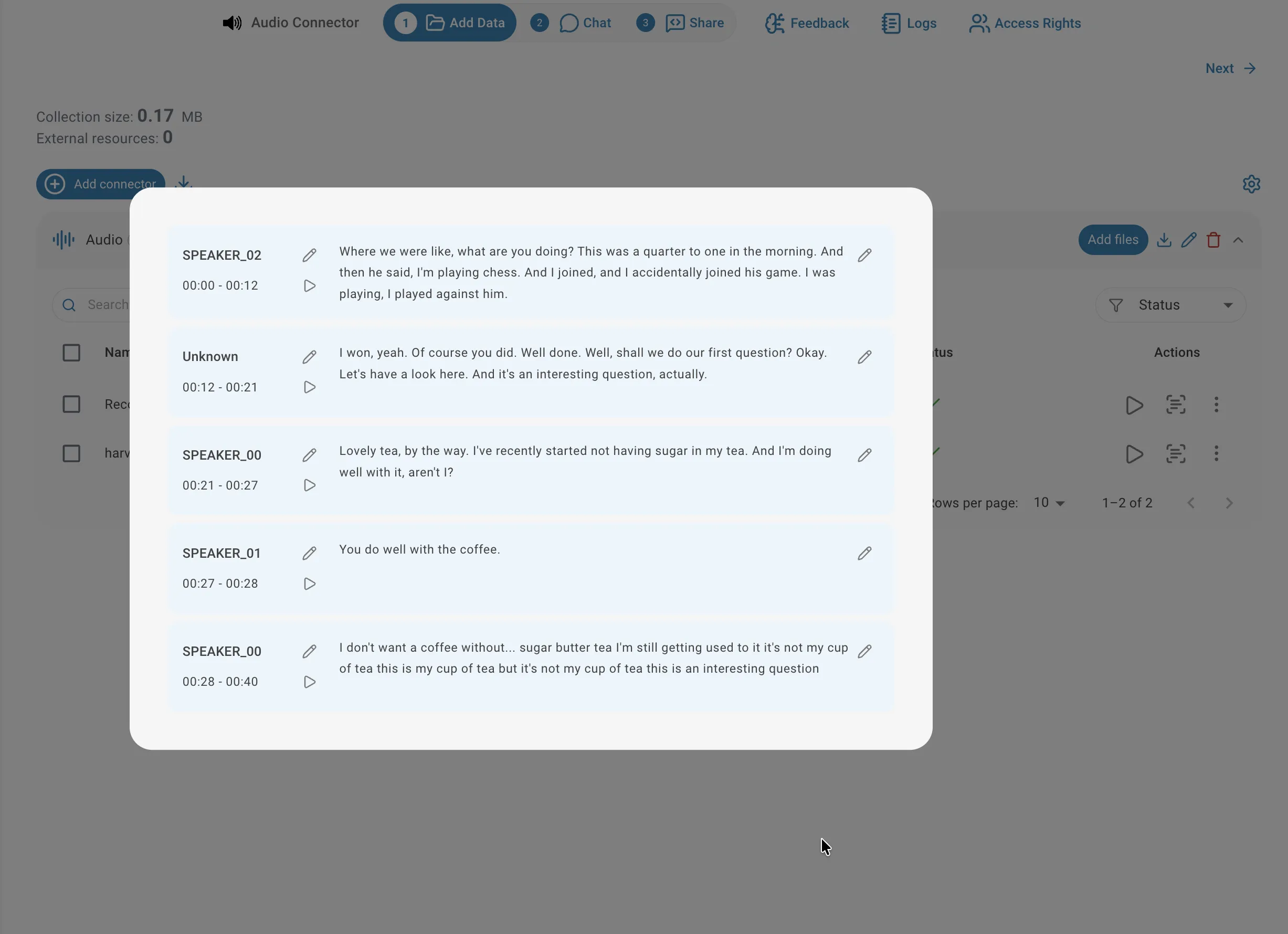
Écouter l'audio
Pour écouter l'audio d'un segment spécifique, cliquez sur l'icône de lecture à côté du segment :
Renommer les locuteurs
Les labels génériques (SPEAKER_00, SPEAKER_01, …) peuvent être remplacés par de vrais noms directement dans le lecteur de transcription. Cliquez sur l'icône de modification à côté d'un label de locuteur et saisissez le nouveau nom. Il vous sera demandé si vous souhaitez appliquer la modification à tous les segments attribués à ce locuteur dans tout l'enregistrement, ou uniquement au segment actuel. Renommer les locuteurs rend les transcriptions plus lisibles et améliore la précision des réponses aux questions portant sur un locuteur spécifique.
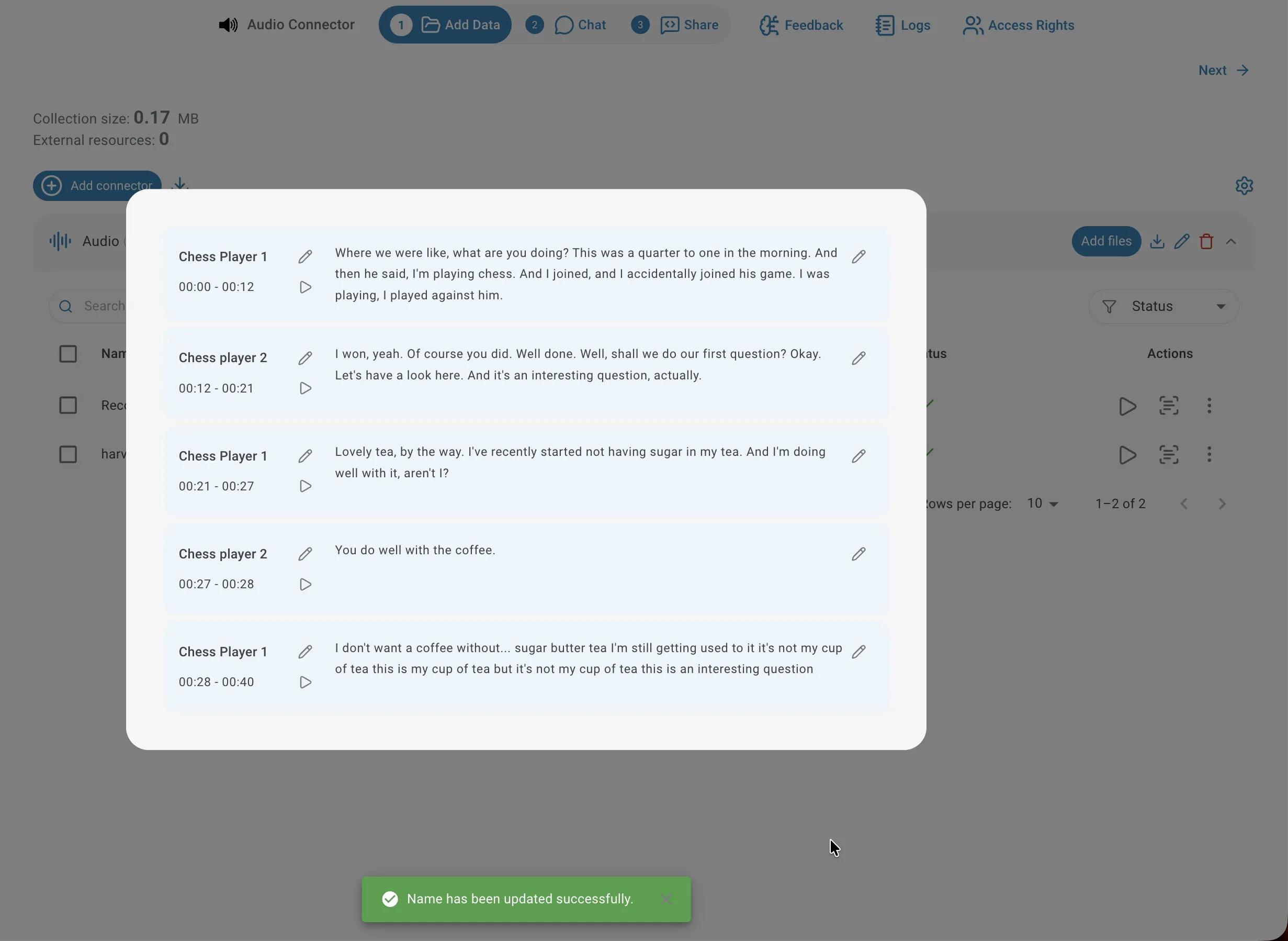
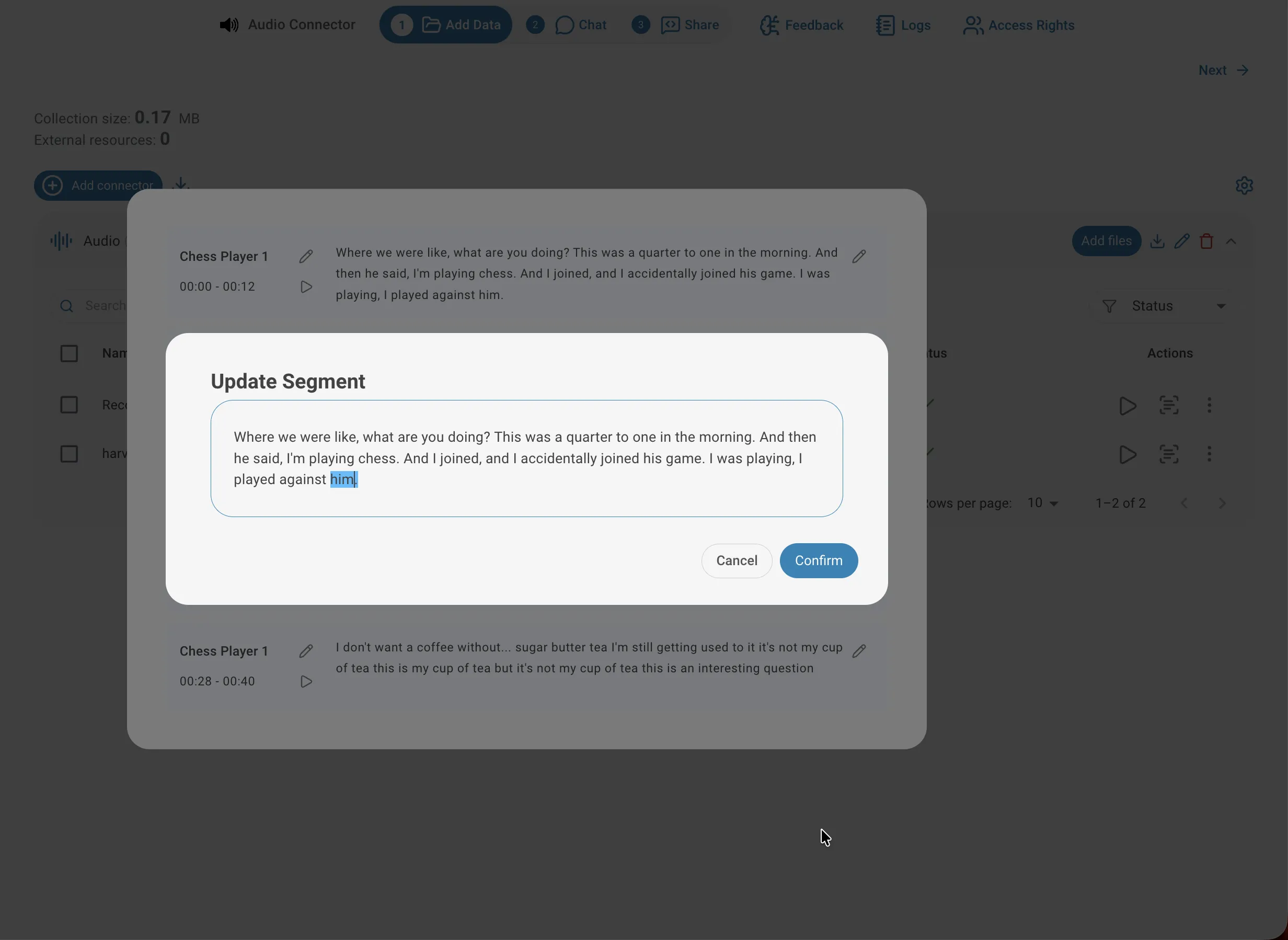
Corriger le texte d'un segment
La transcription automatique peut parfois mal reconnaître des noms propres, des termes techniques ou des accents prononcés. Pour corriger une erreur, cliquez sur l'icône de modification à droite du segment pour ouvrir la boîte de dialogue Mettre à jour le segment, corrigez le texte et confirmez. Le texte mis à jour est réindexé immédiatement et utilisé dans toutes les requêtes futures — corriger les termes clés peut améliorer sensiblement la qualité des réponses.
Poser des questions sur votre audio
Une fois l'audio indexé, basculez vers l'onglet Chat pour poser des questions sur le contenu en langage naturel. QAnswer parcourt l'intégralité de la transcription et génère une réponse fondée sur ce qui a réellement été dit. Vous pouvez poser des questions factuelles comme « Quel était le sujet principal abordé ? », demander un résumé d'un enregistrement, ou interroger un locuteur spécifique comme « Qu'a dit Jean à propos de l'échéance du projet ? ». L'assistant s'appuie uniquement sur la transcription indexée, ce qui garantit des réponses fidèles au contenu source.
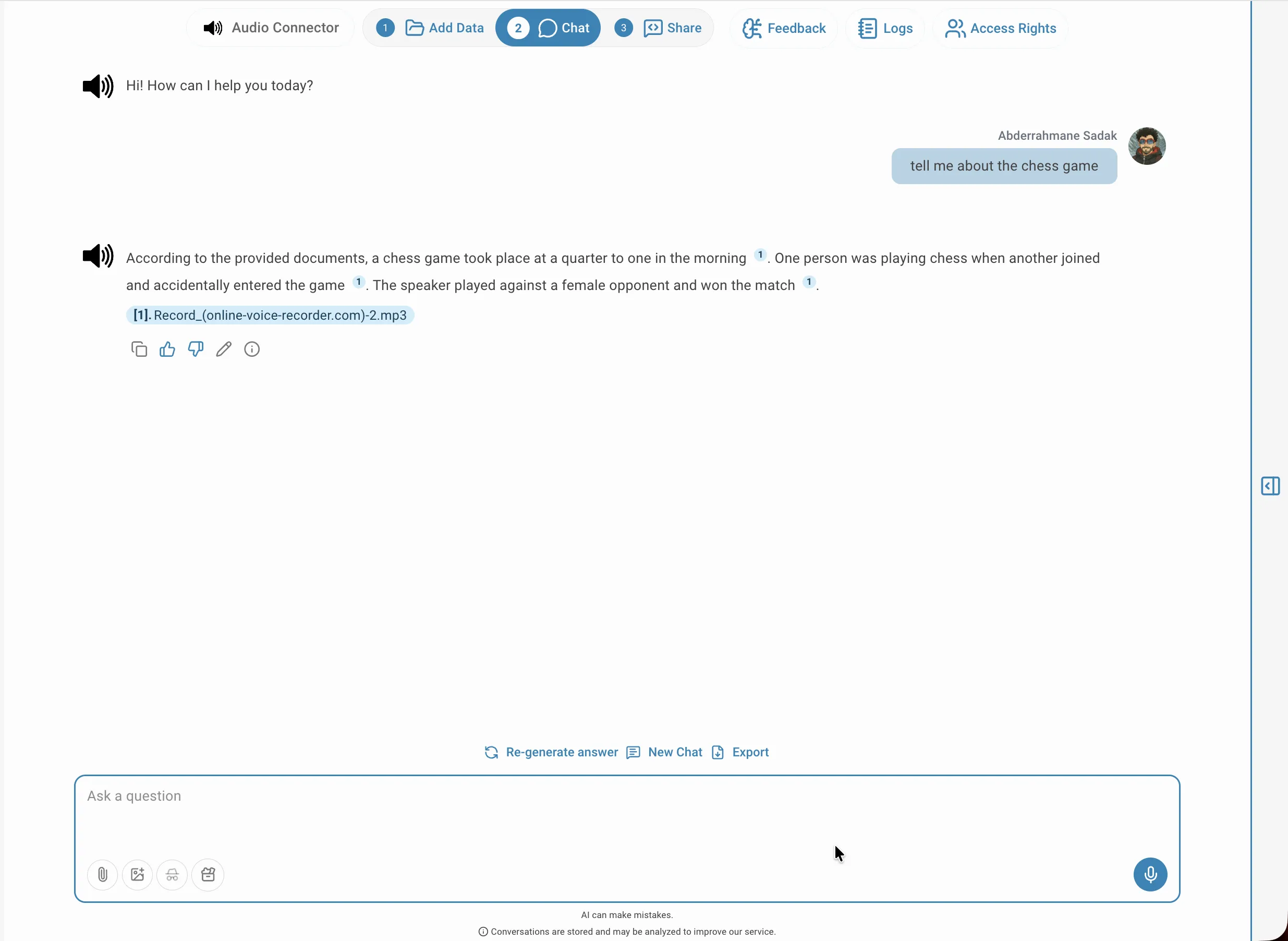
Source mise en évidence
Chaque réponse inclut des citations numérotées qui renvoient au segment exact de la transcription. Cliquer sur une citation ouvre le lecteur de transcription avec le passage pertinent mis en évidence, affichant le label du locuteur et l'horodatage pour vous permettre de vérifier le contexte ou d'écouter ce moment précis dans l'audio. Cela facilite le contrôle de la provenance d'une réponse et la détection des éventuelles erreurs de transcription susceptibles d'affecter la précision.