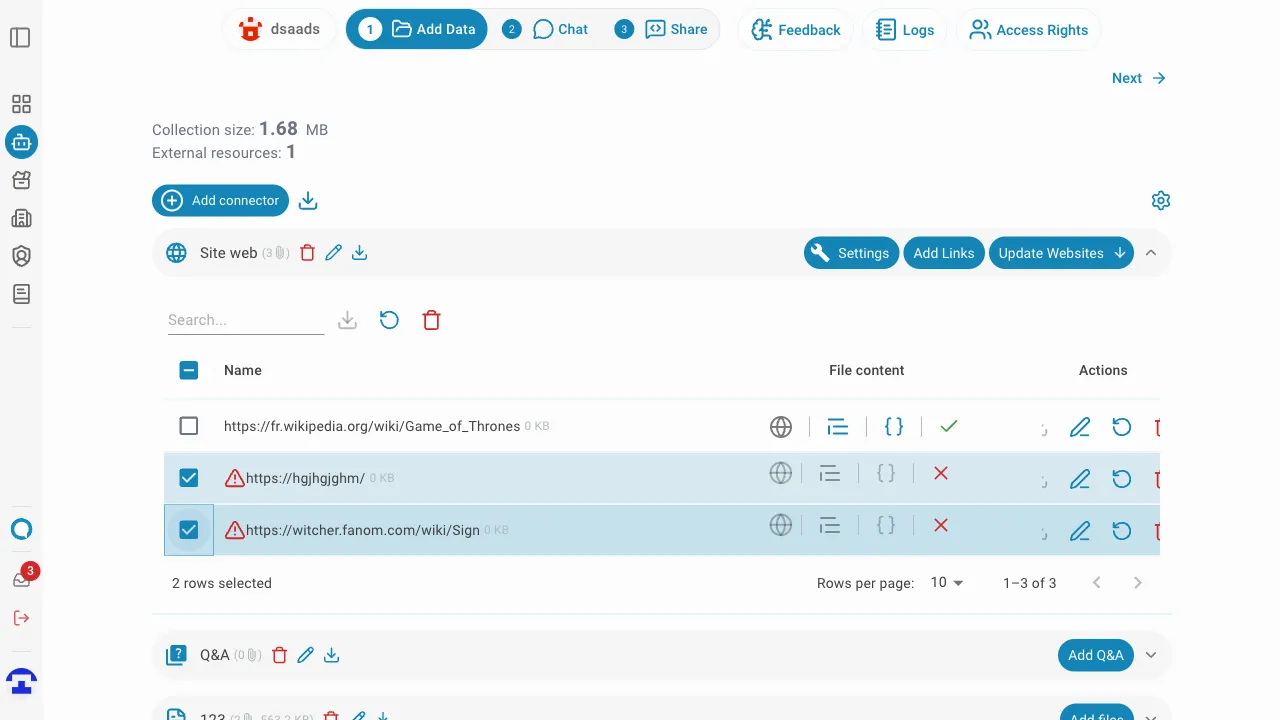
Website - Datenquelle
Verwenden Sie eine einzelne Webseite oder eine gesamte Website als Datenquelle. Dieser Abschnitt beschreibt die Konfiguration des Website-Crawlings.
Klicken Sie auf Website um eine Webseite oder Website als Datenquelle hinzuzufügen:
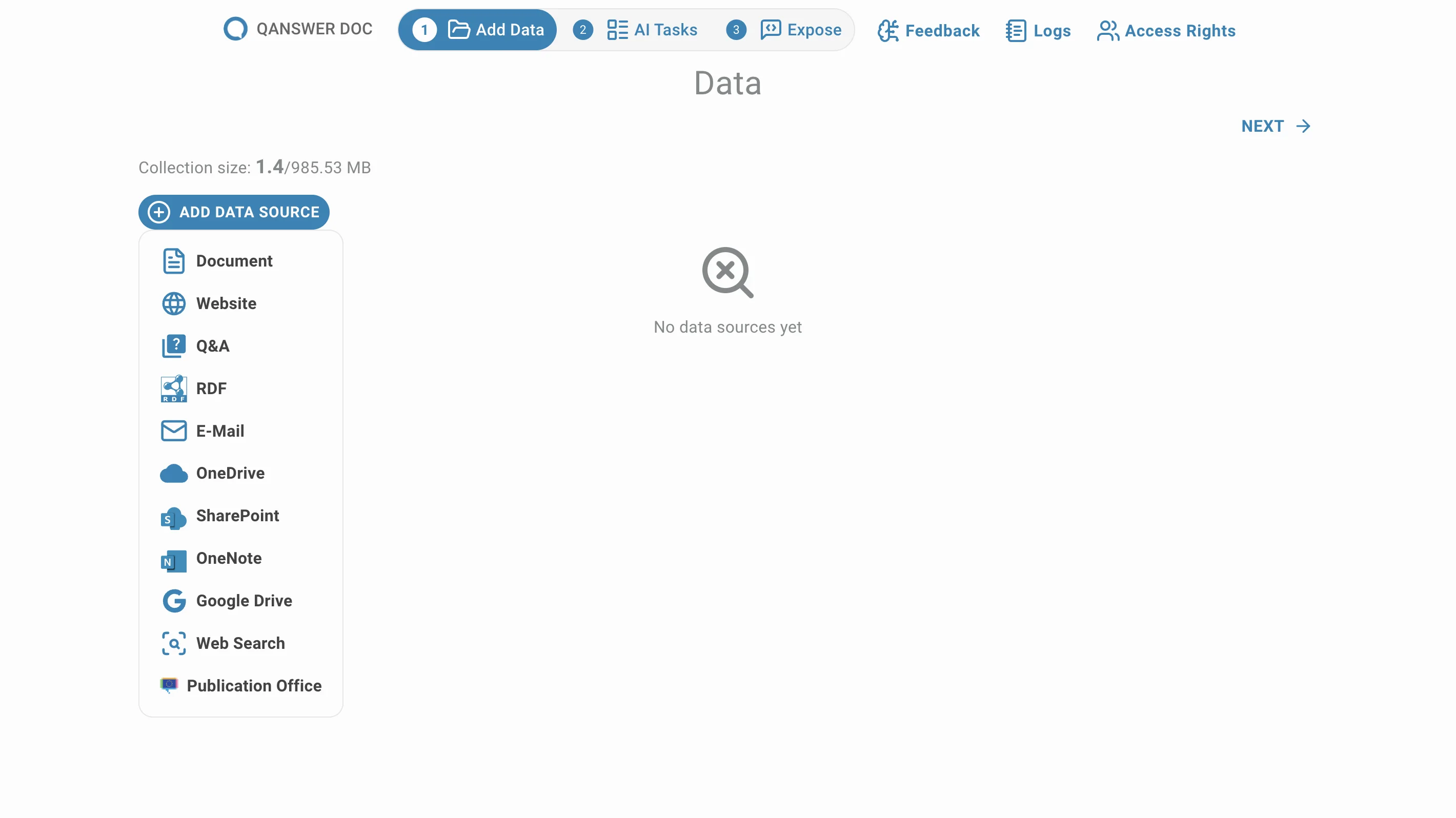
Folgende Seite öffnet sich:
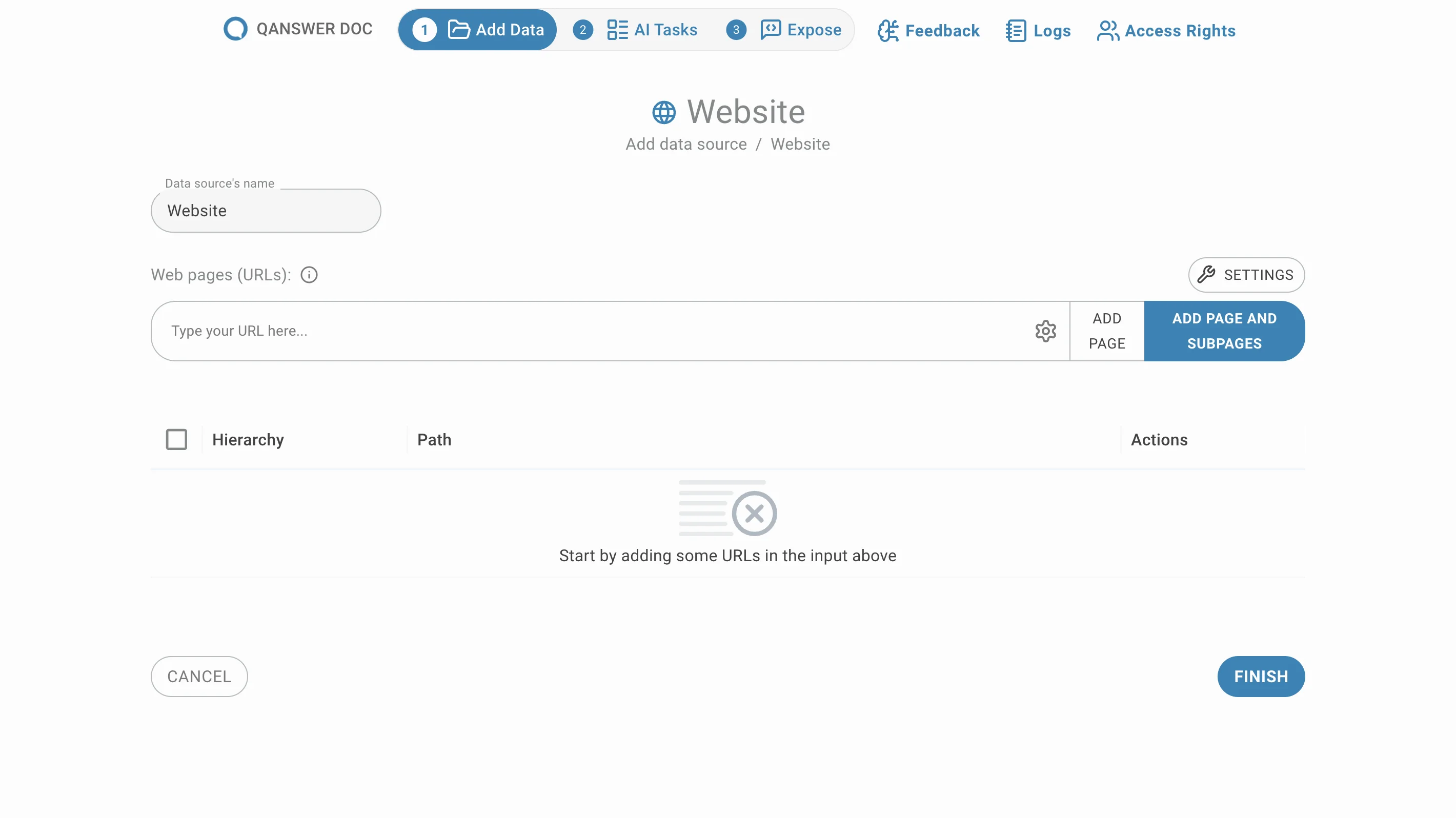
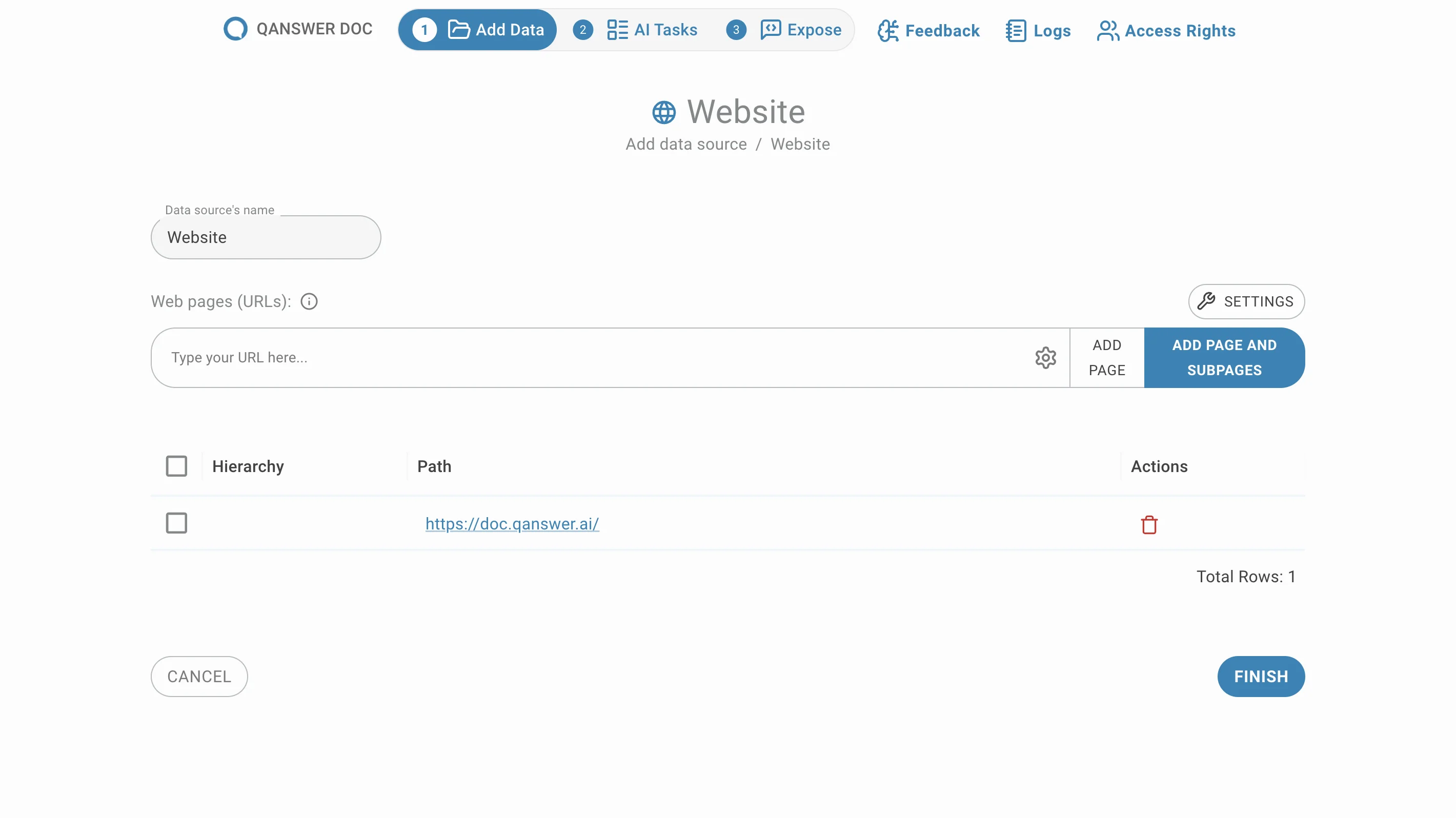
Manuell ausgewählte URLs hinzufügen
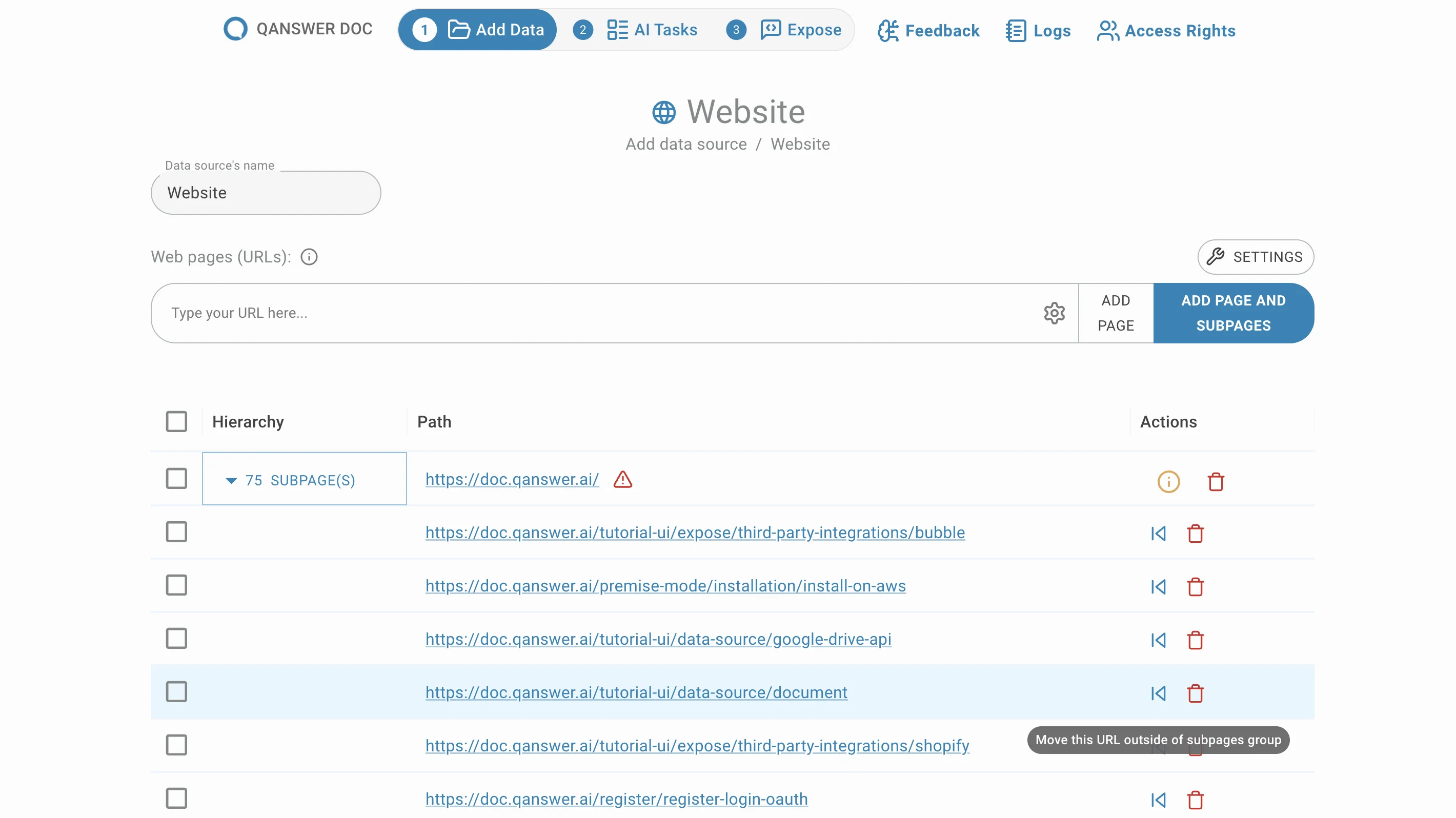
Geben Sie die URLs der gewünschten Seiten ein und klicken Sie auf Seite hinzufügen oder drücken Sie Enter. Ihre URLs erscheinen in der Liste unten:
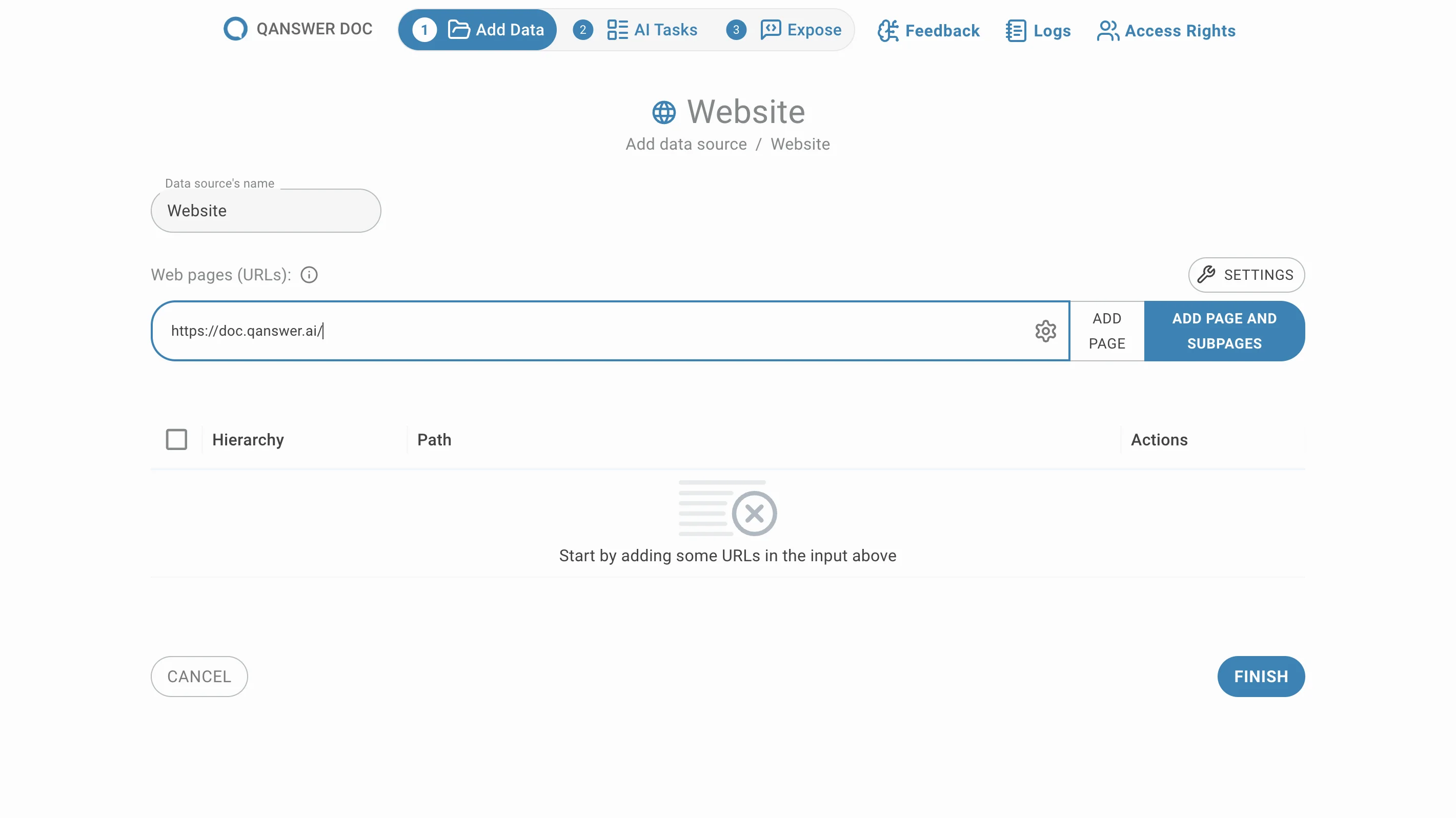
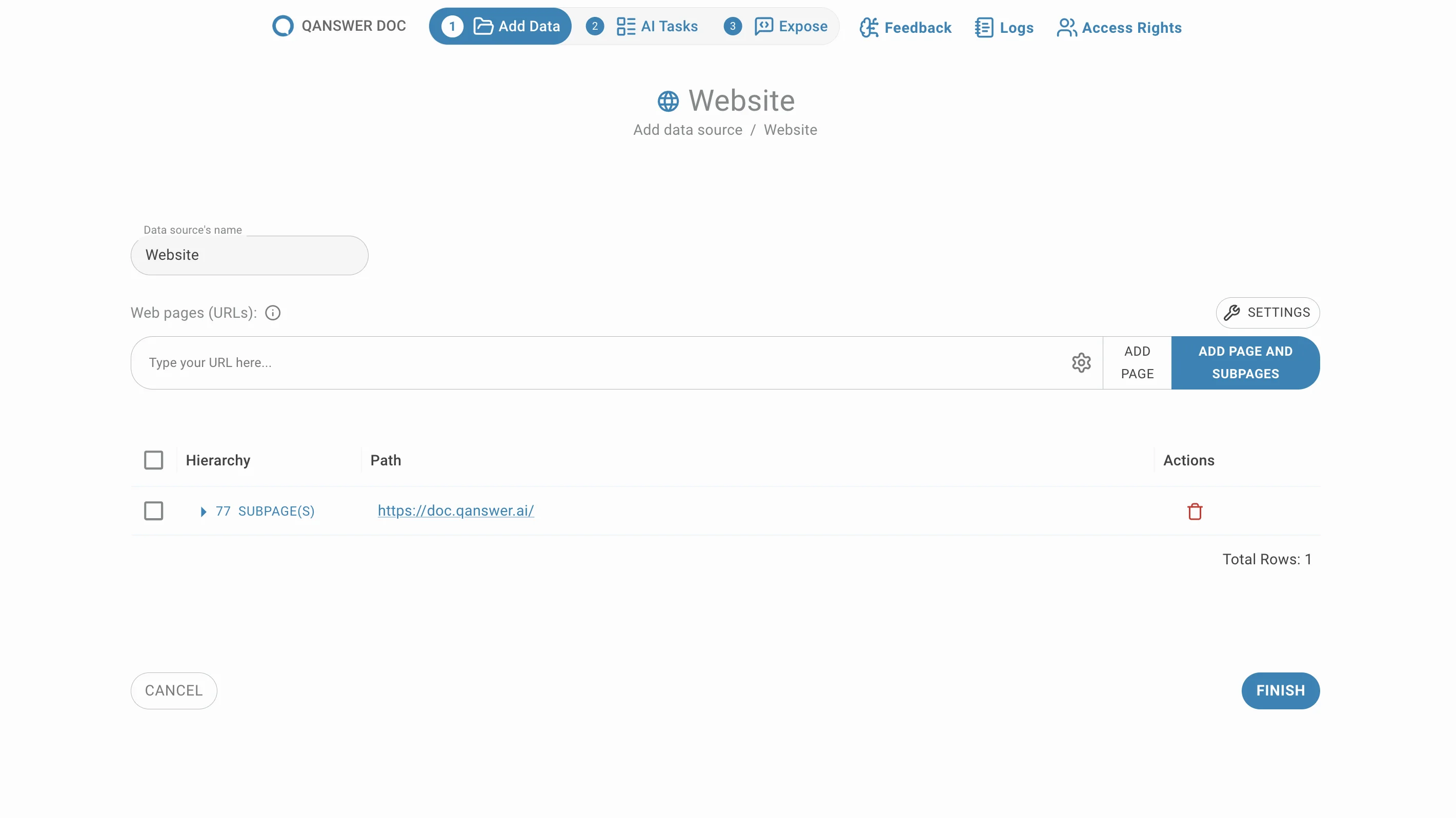
Eine gesamte Website crawlen
Geben Sie die URL einer Website ein und klicken Sie auf Seite und Unterseiten hinzufügen. Alle Unterseiten dieser URL werden extrahiert und standardmäßig gruppiert aufgelistet.
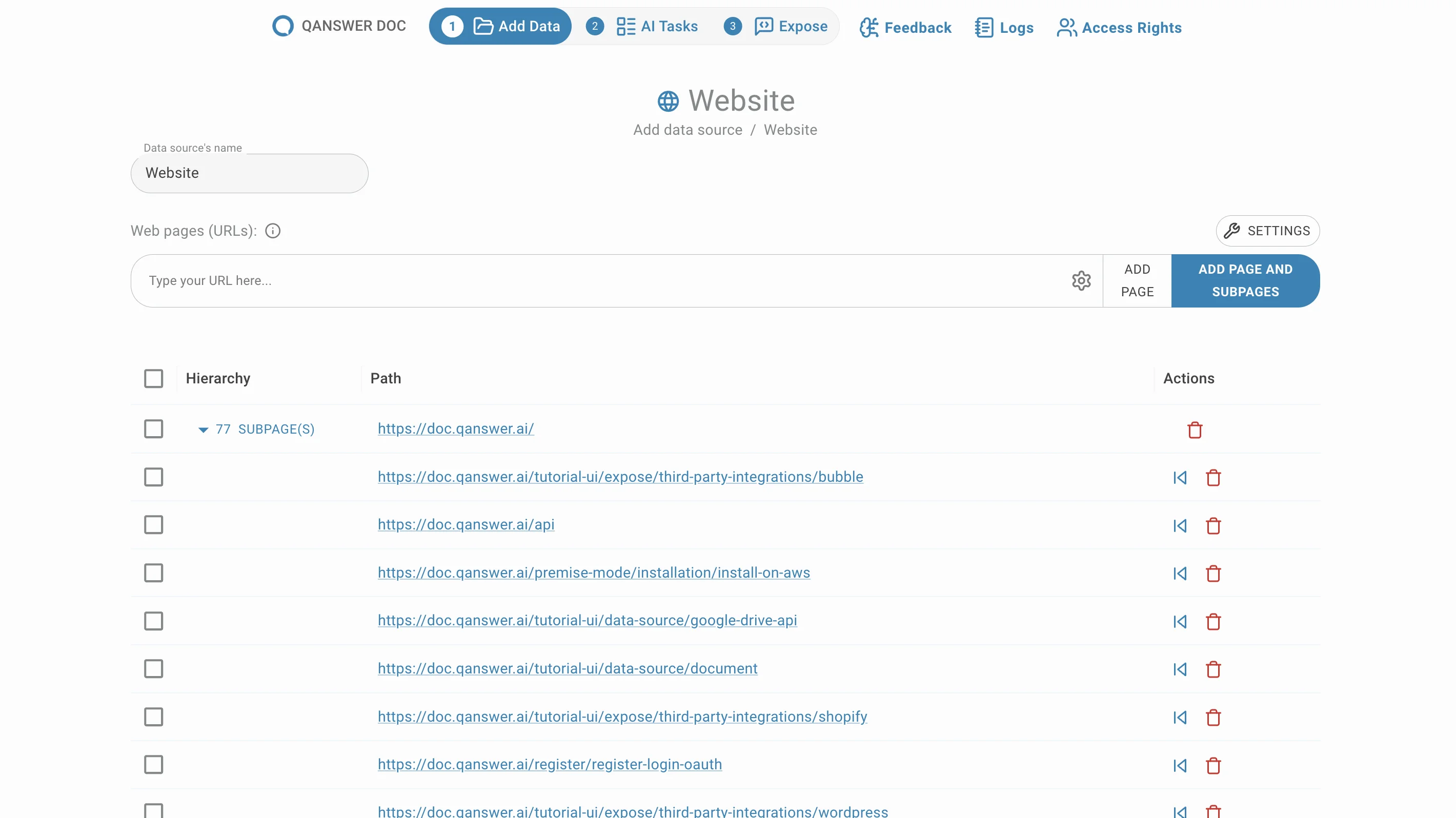
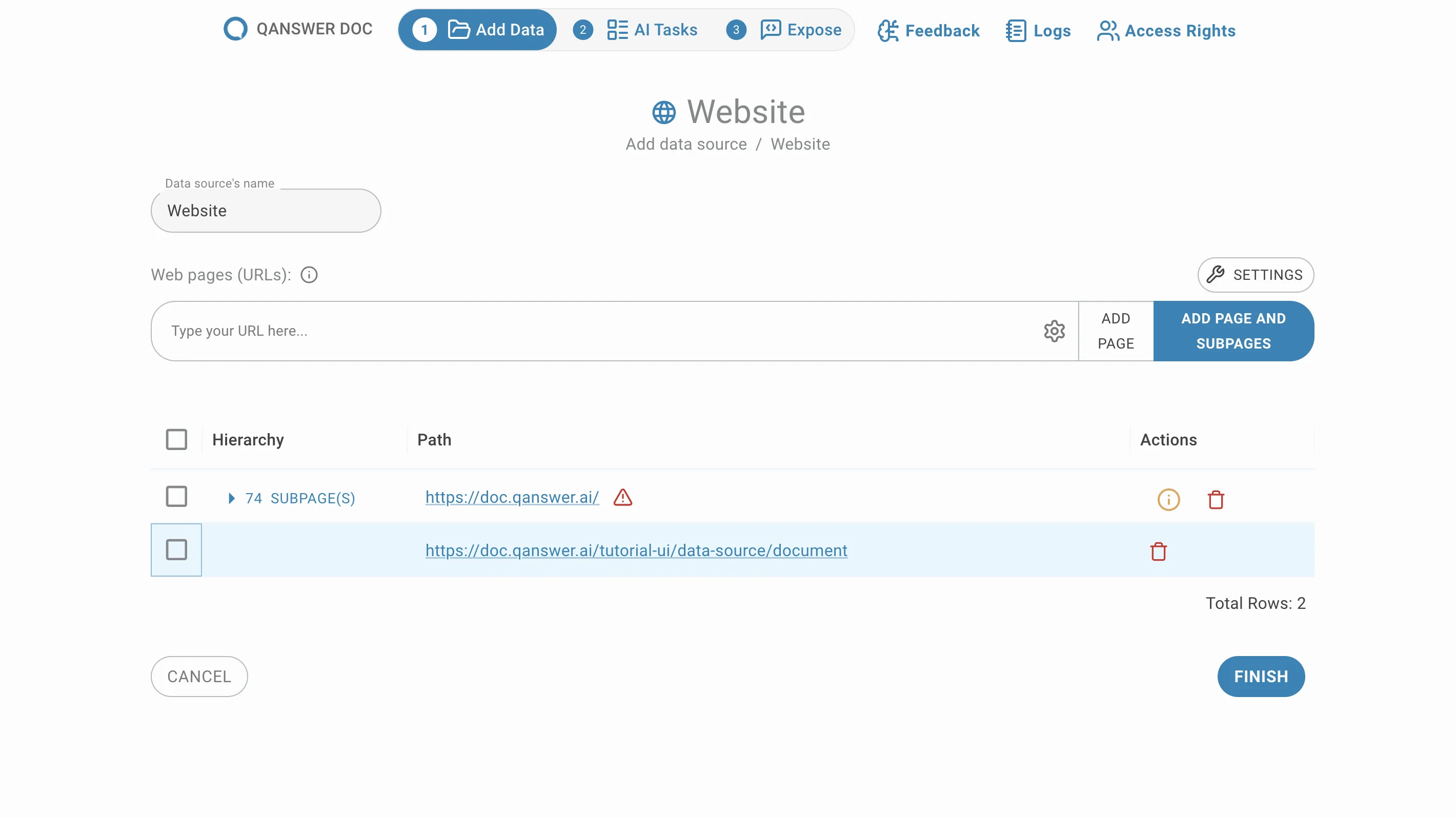
Unterseiten löschen
Entfernen Sie unerwünschte Unterseiten durch Klicken auf die Löschen-Schaltfläche in der Aktion Spalte.
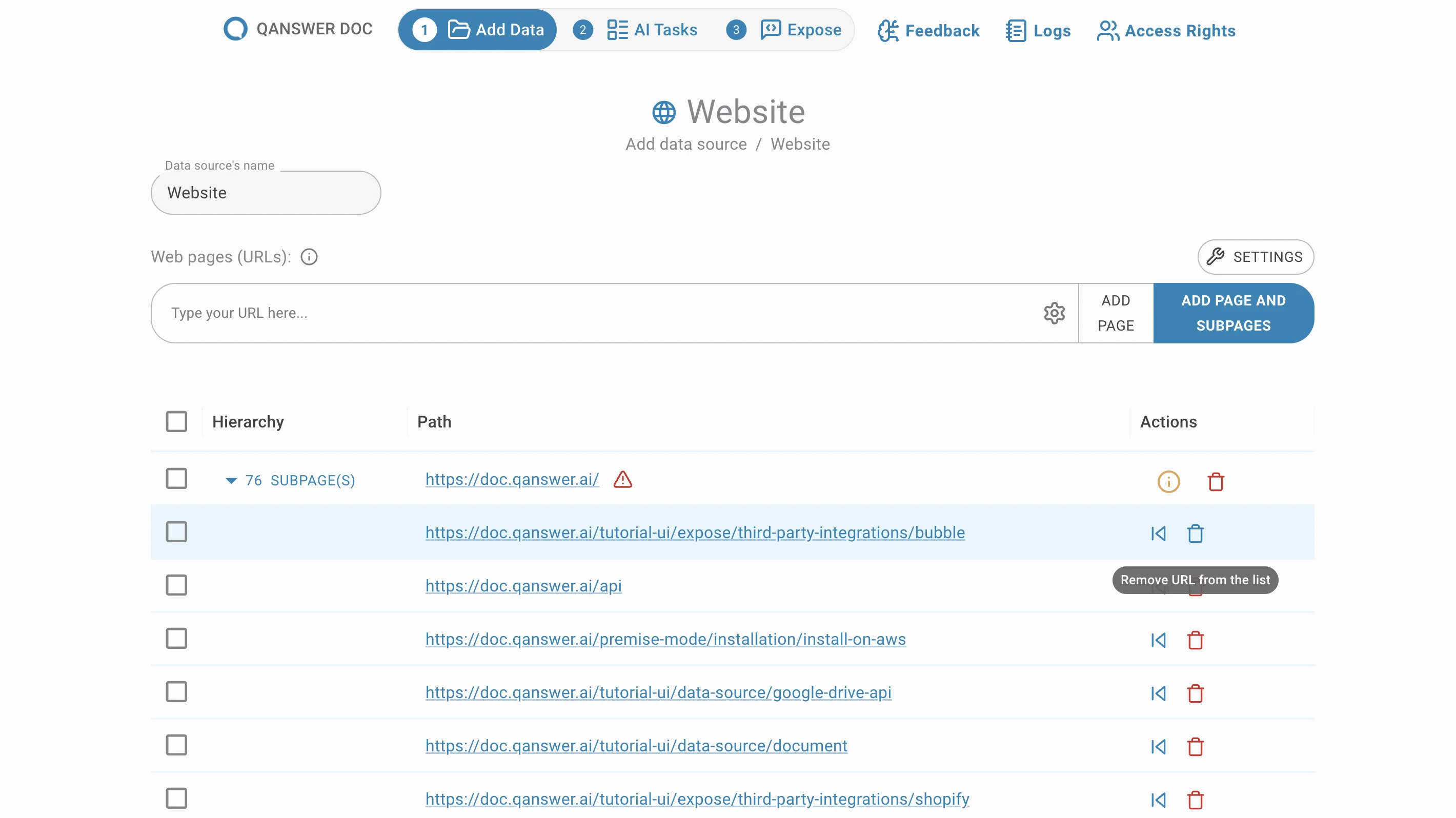
Unterseiten verschieben
Unterseiten sind standardmäßig gruppiert. Verschieben Sie sie aus ihrer Gruppe durch Klicken auf Verschieben in der Aktion Spalte.
Übersprungene Links filtern
Übersicht
Beim Extrahieren von Links können einige URLs übersprungen werden – z.B. durch Zeitüberschreitungen oder Website-Einschränkungen (wie robots.txt).
Ein Info-Symbol kann erscheinen. Standardmäßig werden Links übersprungen, die die Original-URL nicht enthalten, da diese zu einer externen Website gehören könnten.
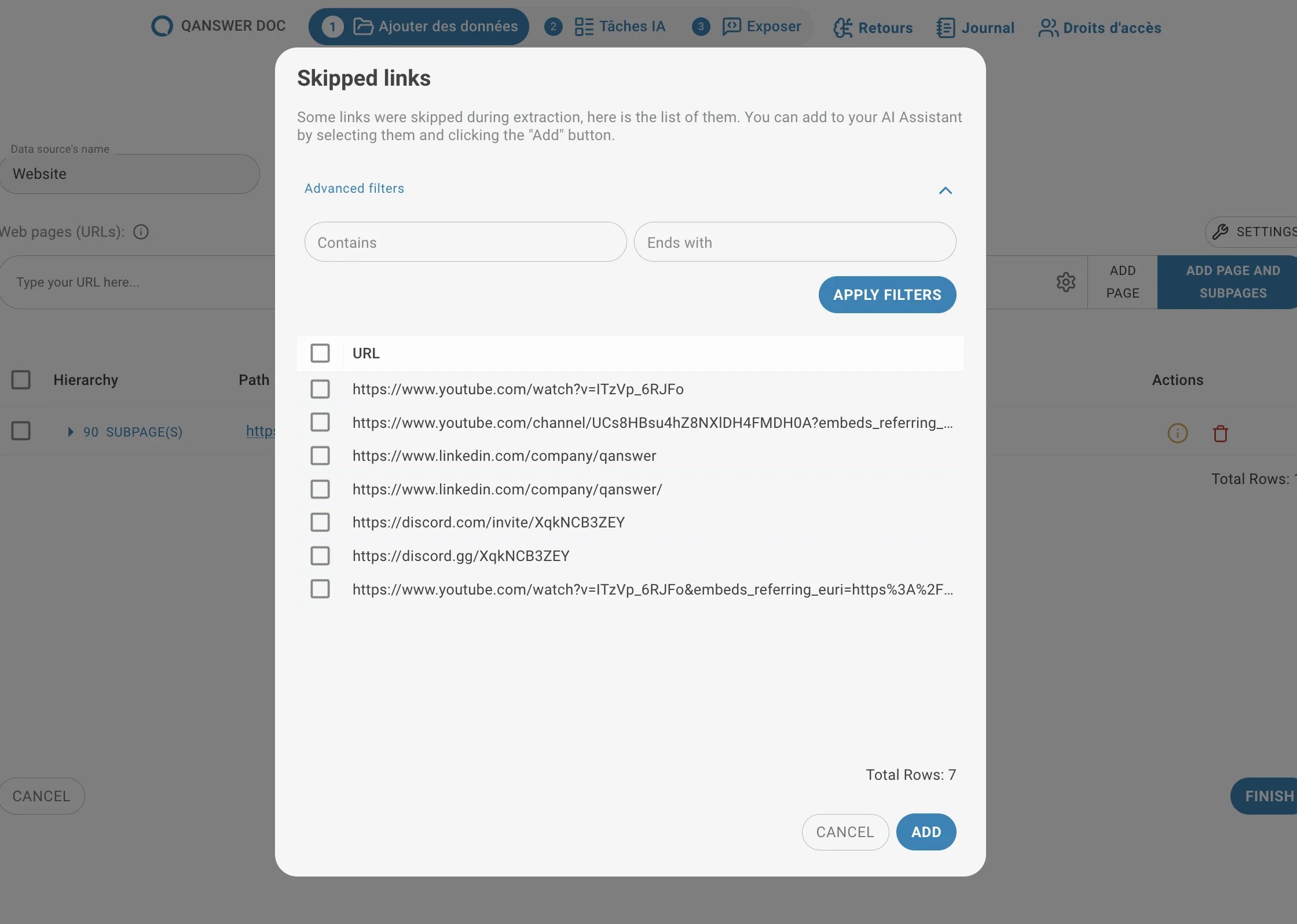
Das Modal für übersprungene Links ermöglicht die Überprüfung dieser URLs und deren Hinzufügen zum Datensatz.
Zwei Filter helfen bei der Verwaltung großer Listen:
- Enthält
- Endet mit
Diese Filter wählen URL-Gruppen anhand einfacher Textmuster aus.
Funktionsweise
Geben Sie einen Wert in einen der Filter ein:
- Enthält — wählt URLs aus, die die angegebene Zeichenkette enthalten.
Beispiel: Filtern mit "/blog/" wählt alle übersprungenen Links unter einem /blog/-Unterpfad aus. - Endet mit — wählt URLs aus, die mit dem angegebenen Text enden.
Beispiel: Filtern mit ".pdf" wählt alle Links zu PDF-Dateien aus. - Klicken Sie auf Filter anwenden.
Alle passenden URLs werden automatisch ausgewählt.
Wichtiges Verhalten: Additive Auswahl
Auswahlen sind additiv.
Jeder neue Filter fügt passende URLs zur aktuellen Auswahl hinzu.
Manuell ausgewählte URLs bleiben immer ausgewählt.
Neue Filter entfernen keine zuvor ausgewählten URLs.
Beispiel:
- URL 1 manuell auswählen.
- Filter anwenden, der URL 2 und URL 3 auswählt.
- Endergebnis: URLs 1, 2 und 3 sind ausgewählt.
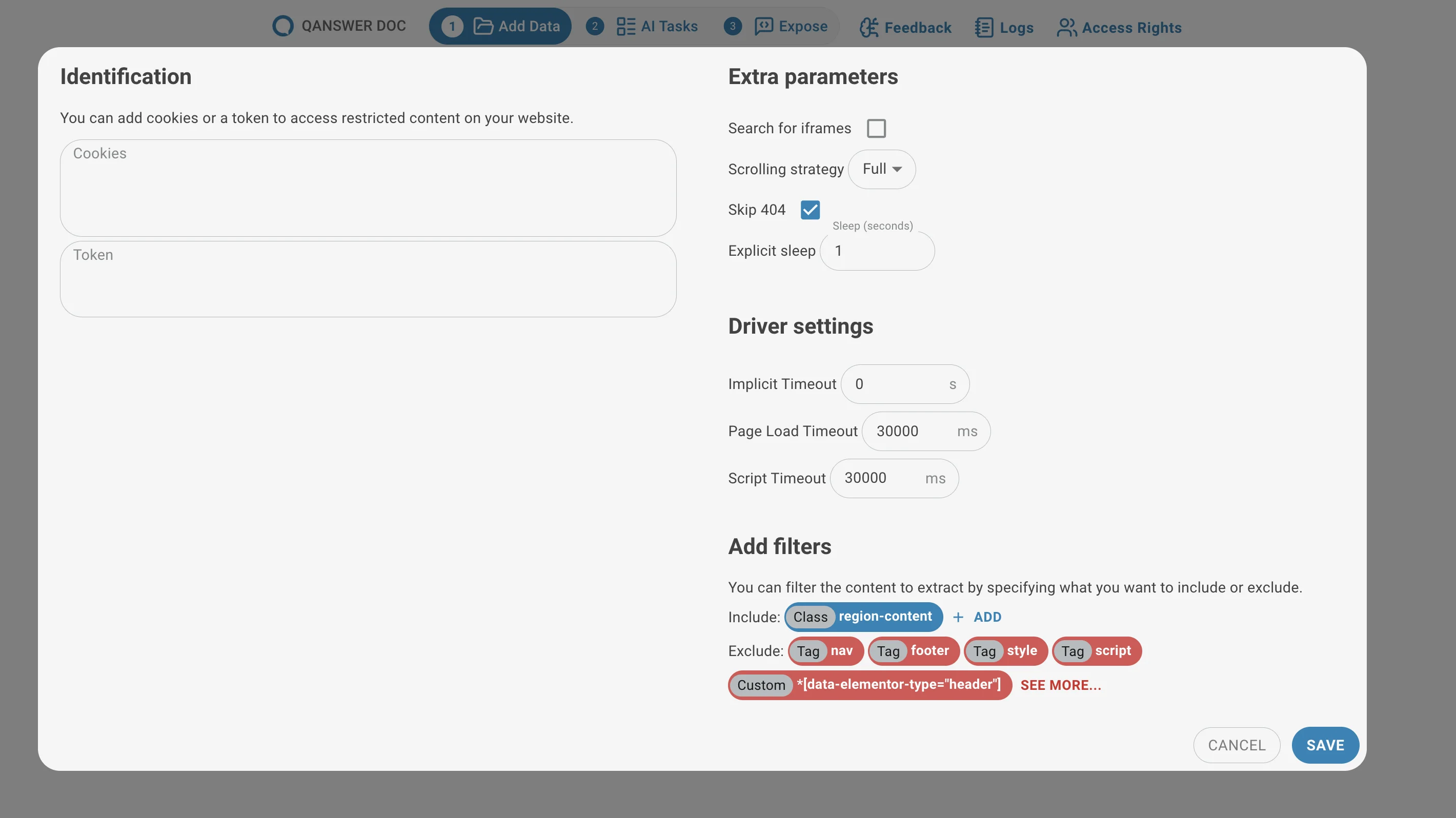
Erweiterte Einstellungen (optional)
Passen Sie bei Bedarf die Crawling-Parameter an. Standardwerte eignen sich für die meisten Anwendungsfälle. Verfügbare Einstellungen:
Automatische Link-Erkennung (nur für das Extrahieren von Hyperlinks)
- Maximale Tiefe: Steuert, wie viele Ebenen tief der Crawler Links folgt.
- Zeitüberschreitung: Legt das Zeitlimit für die Link-Erkennung fest. Der Crawler stoppt frühzeitig, wenn dieses Limit erreicht wird.
Authentifizierung (für Link- und Seiten-Indizierung)
- Cookies: Manche Websites erfordern Cookies für den Zugriff. Geben Sie diese als JSON-Wörterbuch an.
{ "session": "abc123", "user_id": "789xyz" } - Token: Manche Websites erfordern ein Token für den Zugriff.
{ "token_name": "Bearer your_token_here", }
Zusätzliche Parameter (für Link-Extraktion und Seiten-Indizierung)
- Iframes durchsuchen: Steuert, ob der Crawler Iframe-Inhalte prüft. Standardmäßig "auto"; kann bei Bedarf erzwungen werden.
- Scroll-Strategie: Steuert, wie der Crawler die Seite scrollt, um verzögert geladene Inhalte auszulösen.
- 404 überspringen: Wenn aktiviert, ignoriert der Crawler fehlerhafte Links (404-Fehler) beim Sammeln von Links.
Treiber-Einstellungen (für Link-Extraktion und Seiten-Indizierung)
- Implizite Zeitüberschreitung: Die feste Wartezeit vor jedem Seitenlade-Versuch.
- Seitenlade-Zeitüberschreitung: Wie lange der Crawler auf eine vollständige Seitenladung wartet.
- Skript-Zeitüberschreitung: Wie lange der Crawler auf die Ausführung von JavaScript wartet.
Filter hinzufügen (für Link-Extraktion und Seiten-Indizierung)
- Einschließen: HTML-Tags, auf die sich der Crawler beim Sammeln von Links oder Inhalten konzentrieren soll (z.B.
<div>,<a>). - Ausschließen: HTML-Tags oder Abschnitte, die der Crawler ignorieren soll (z.B.
<script>,<footer>).
Erstellen
Klicken Sie auf Fertig um zur Datenquellenseite zu gelangen. Die ausgewählten Seiten beginnen sofort mit dem Crawling.
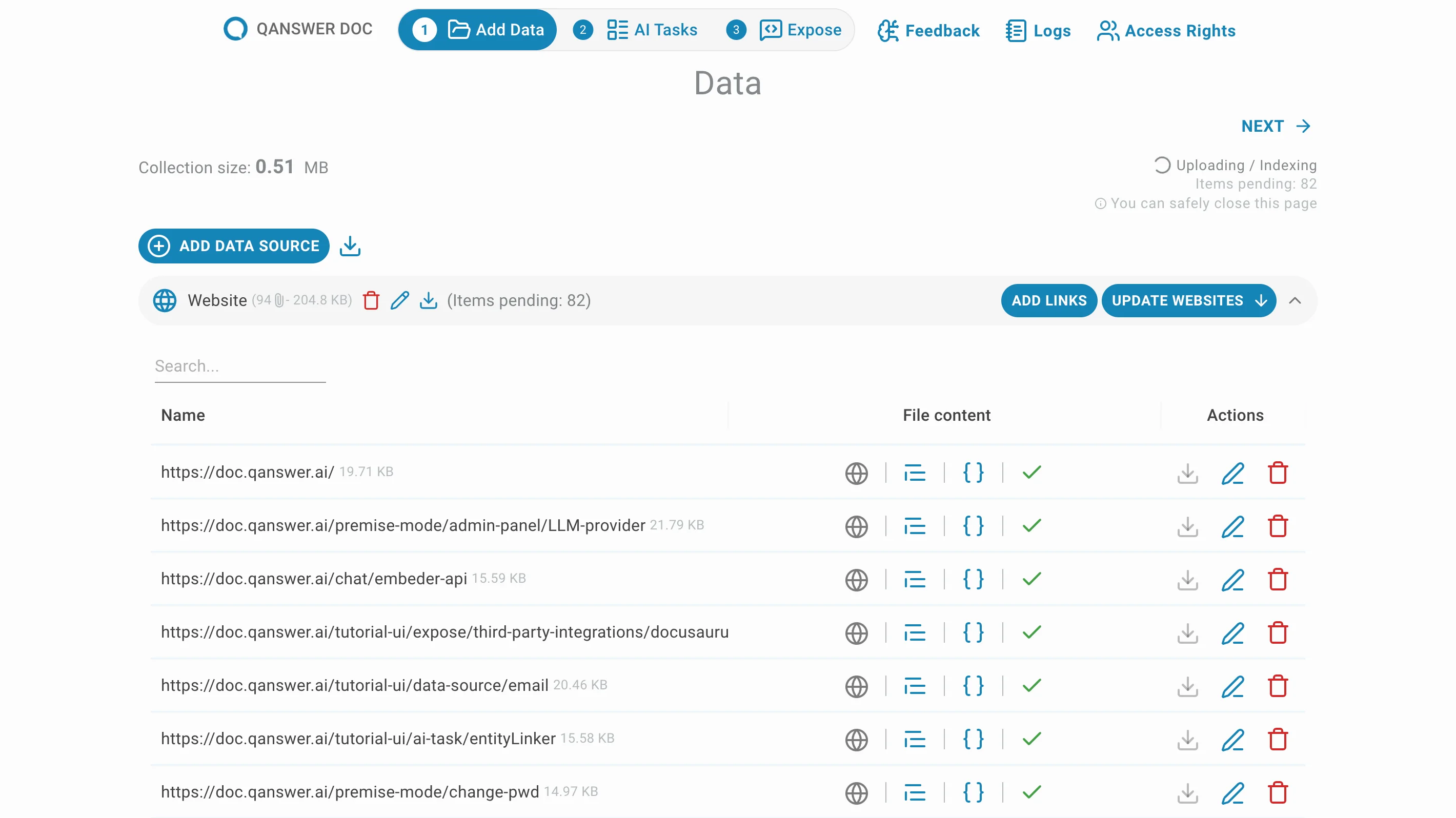
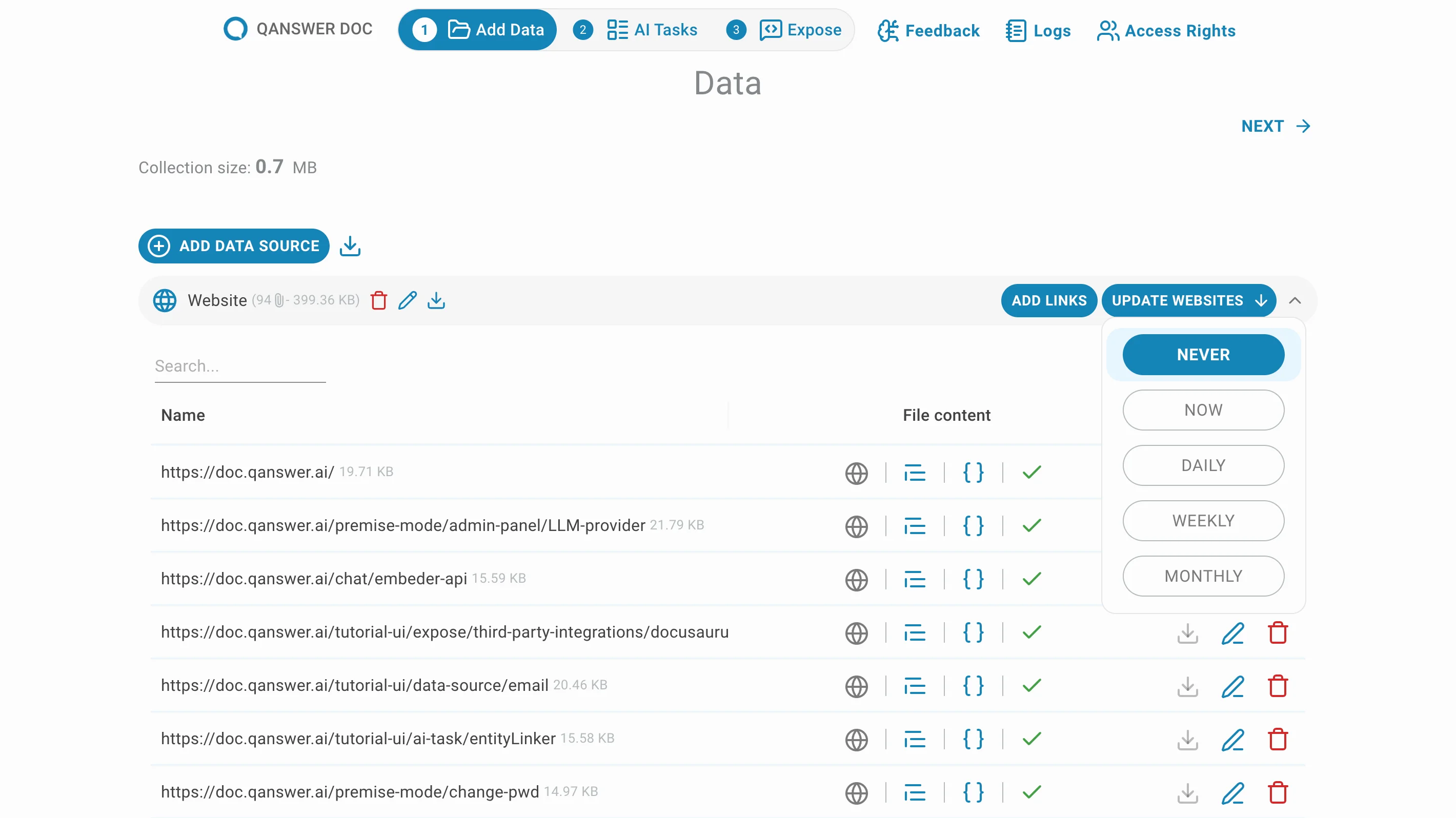
Klicken Sie auf Websites aktualisieren um die Häufigkeit automatischer Crawling-Aktualisierungen festzulegen.
Stapelaktionen für ausgewählte Links
Sie können mehrere Links gleichzeitig über die Kontrollkästchen auf der linken Seite jeder Zeile auswählen.
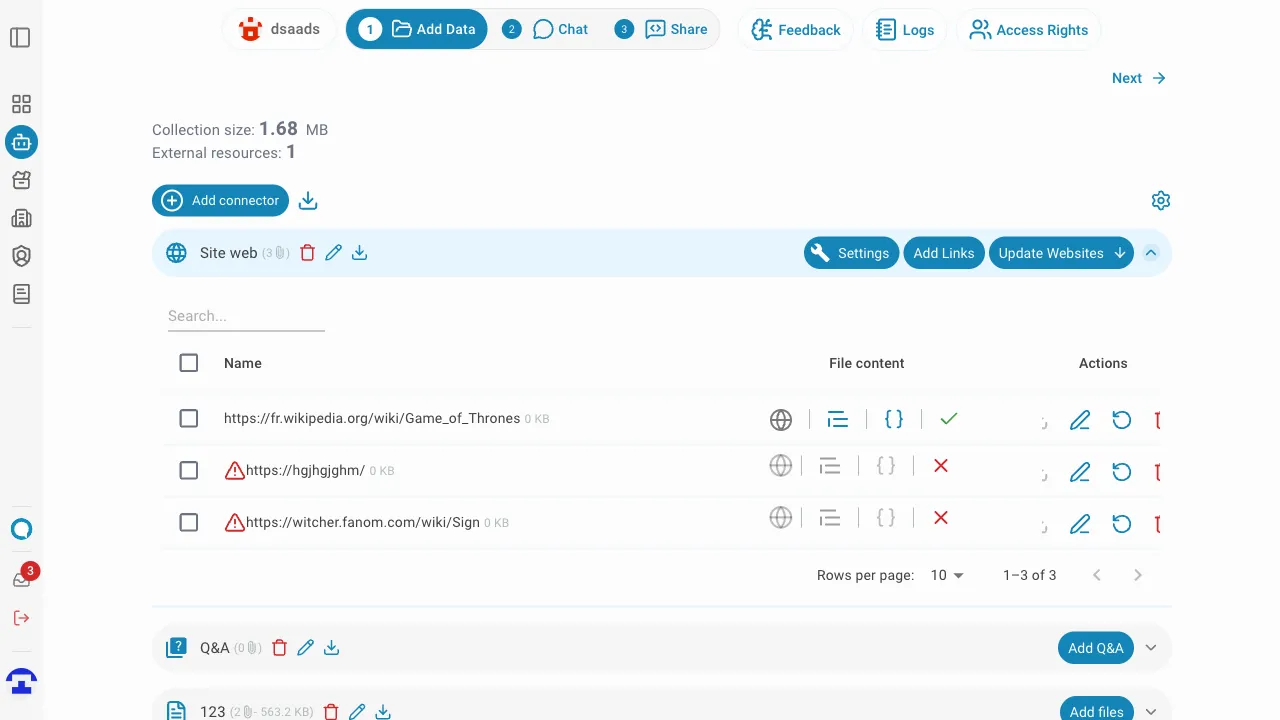
Sobald ein oder mehrere Links ausgewählt sind, erscheint eine Stapelaktions-Leiste über der Tabelle mit folgenden Aktionen:
- Ausgewählte Links erneut versuchen — crawlt alle ausgewählten Website-Links parallel erneut. Nützlich für das erneute Indizieren von Links, die zuvor fehlgeschlagen sind oder aktualisiert werden müssen.
- Löschen — entfernt alle ausgewählten Links dauerhaft aus dem Connector.