Parsing-Optionen
Der Dialog „Parsing-Optionen“ steuert, wie QAnswer Ihre hochgeladenen Dokumente in einen durchsuchbaren Index umwandelt. An einer Stelle können Sie das Embedding-Modell wählen, das Aufteilen der Dokumente in Chunks einstellen, zwischen der hochpräzisen und der schnellen Indexierungs-Pipeline wechseln, den LLM-Indexierungs-Prompt anpassen und nach jeder Änderung eine vollständige Neuindexierung erzwingen.
Dialog öffnen
Öffnen Sie die Seite Daten hinzufügen Ihres Assistenten und klicken Sie auf die Schaltfläche
Der Dialog ist in zwei Registerkarten gegliedert:
- Indexierung — wie Text aus Ihren Dateien extrahiert und der Assistent neu verarbeitet wird.
- Embedding & Chunking — welches Embedding-Modell verwendet wird und wie Dokumente in Chunks aufgeteilt werden.
Registerkarte „Indexierung“
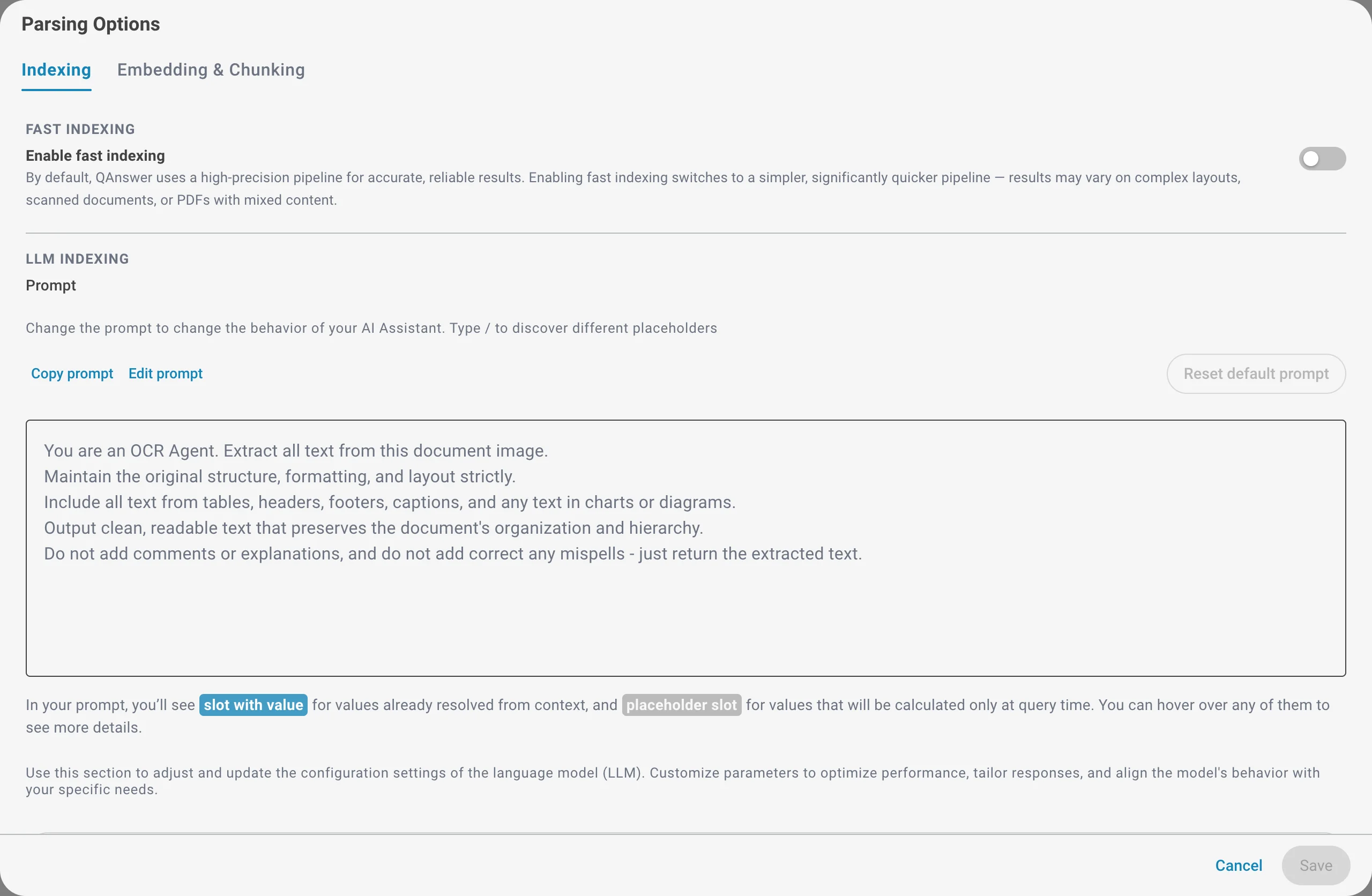
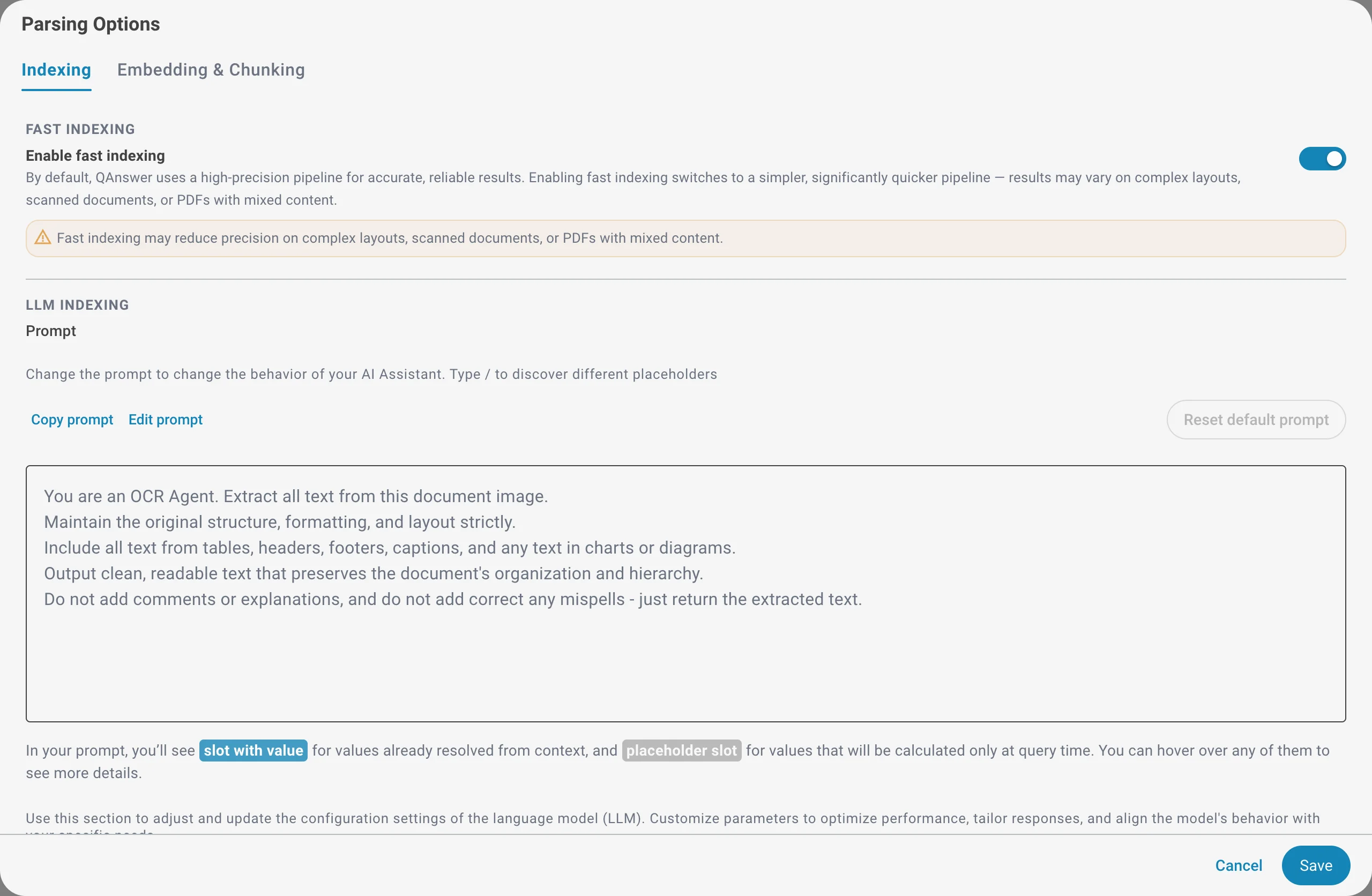
Schnelle Indexierung
Standardmäßig verwendet QAnswer eine hochpräzise Pipeline für genaue, zuverlässige Ergebnisse. Das Aktivieren der schnellen Indexierung wechselt zu einer einfacheren, deutlich schnelleren Pipeline. Verwenden Sie sie, wenn Sie große Mengen schnell indexieren müssen und Ihre Dokumente ein einfaches Layout haben.
LLM-Indexierung
Sofern Ihr Tarif dies unterstützt, liest ein Sprachmodell jedes Dokument während der Indexierung — besonders nützlich für gescannte Seiten und Bilder. Sie können den Extraktions-Prompt anpassen und das LLM sowie dessen Parameter (Kontextfenster, maximale Antwortlänge, Temperatur) wählen.
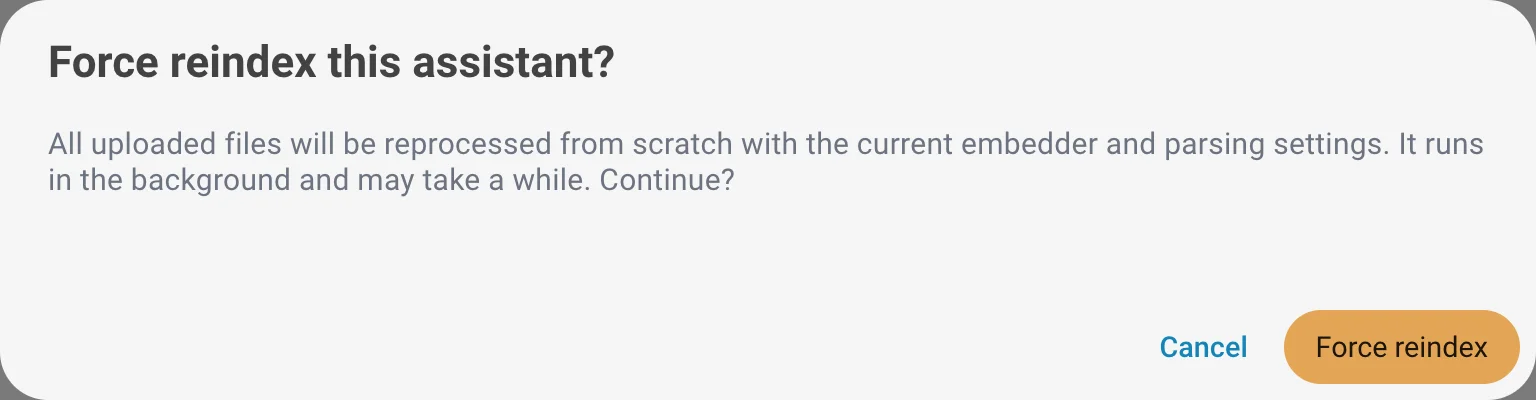
Neuindexierung erzwingen
Verarbeitet alle hochgeladenen Dateien erneut durch die vollständige Pipeline, sodass der gesamte Assistent mit Ihren neuesten Embedder- und Parsing-Einstellungen neu aufgebaut wird. Nützlich nach dem Ändern des Embedding-Modells oder einer Parsing-Option, da bestehende Dateien bis zur Neuverarbeitung die Einstellungen behalten, mit denen sie indexiert wurden.
Vor dem Start der Neuindexierung ist eine Bestätigung erforderlich. Sie läuft im Hintergrund und kann je nach Anzahl und Größe Ihrer Dateien eine Weile dauern.
Registerkarte „Embedding & Chunking“
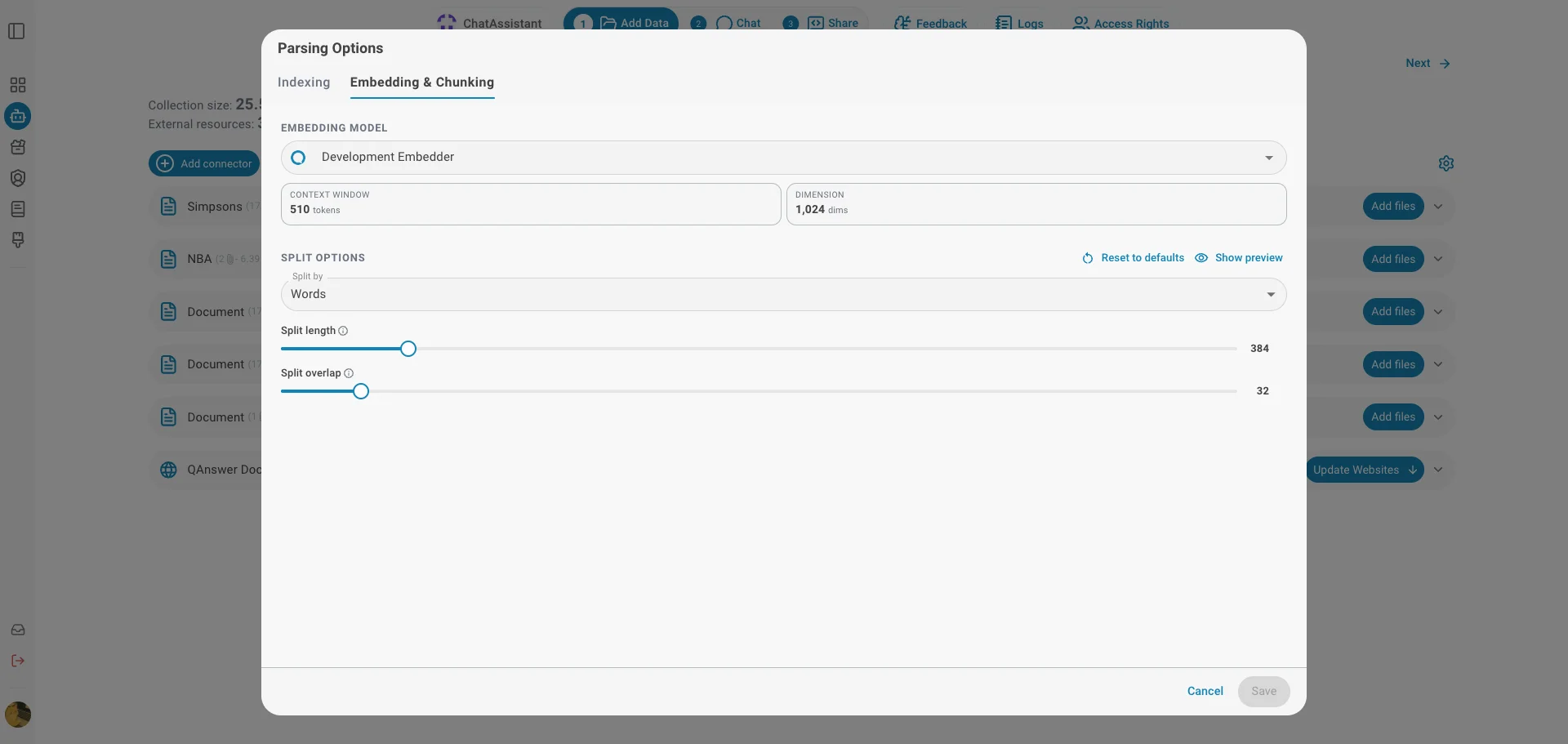
Embedding-Modell
Wählen Sie das Embedding-Modell, mit dem Ihre Dokumente vektorisiert werden. Das Modell bestimmt, wie Text für die semantische Suche dargestellt wird. Für das ausgewählte Modell werden zwei wichtige Eigenschaften angezeigt:
- Kontextfenster — die maximale Anzahl von Tokens, die das Modell auf einmal einbetten kann. Ihre Chunk-Größe muss innerhalb dieses Limits bleiben.
- Dimension — die Größe des Vektors, in den jeder Chunk umgewandelt wird.
Aufteilungs-Optionen
Dokumente werden vor dem Embedding in kleinere Chunks zerlegt. Diese Optionen steuern, wie die Aufteilung erfolgt:
- Aufteilen nach — die Einheit zur Messung jedes Chunks: Wörter, Sätze oder Seiten.
- Aufteilungslänge — wie viele Einheiten jeder Chunk enthält.
- Überlappung — wie viele Einheiten zwischen aufeinanderfolgenden Chunks wiederholt werden, damit an den Chunk-Grenzen kein Kontext verloren geht (bei seitenbasierter Aufteilung auf 0 festgelegt).
Mit „Auf Standard zurücksetzen“ stellen Sie die empfohlenen Aufteilungseinstellungen des gewählten Embedders wieder her.
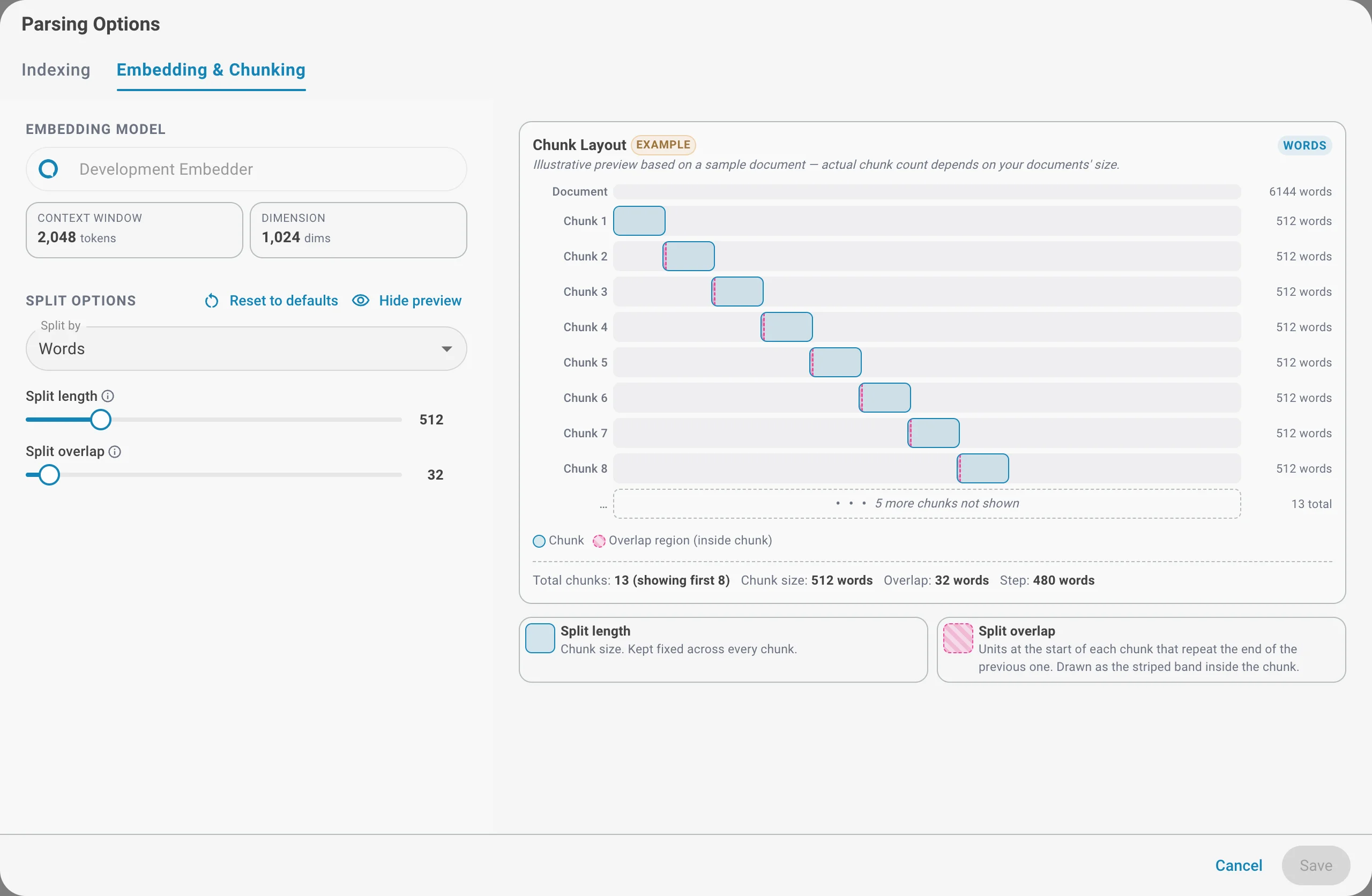
Vorschau der Chunk-Anordnung
Klicken Sie auf „Vorschau anzeigen“, um eine beispielhafte Anordnung zu sehen, wie ein Beispieldokument mit den aktuellen Einstellungen aufgeteilt würde — Chunk-Anzahl, Chunk-Größe, Überlappung und der resultierende Schritt zwischen Chunks. Die Vorschau ist nur ein Beispiel; die tatsächliche Anzahl der Chunks hängt von der Größe Ihrer Dokumente ab.
Änderungen speichern
Die Schaltfläche „Speichern“ ist nur aktiv, wenn es ungespeicherte Änderungen gibt. Wenn Sie das Embedding-Modell geändert haben, müssen Sie die Änderung vor dem Speichern bestätigen, da sie eine vollständige Neuindexierung des Assistenten auslöst.