Audio

Video-Tutorial
Audio
Auf der Tutorials-Seite ansehen →
Audio - Datenquelle
Verwenden Sie eine oder mehrere Audiodateien oder Aufnahmen als Datenquelle für Ihren QAnswer KI-Assistenten. Der Audio-Connector transkribiert Ihre Sprachinhalte in durchsuchbaren Text und ermöglicht es Ihnen, in natürlicher Sprache Fragen zu Meetings, Interviews, Vorlesungen, Podcasts oder anderen Audiomaterialien zu stellen. Sowohl Datei-Uploads als auch Live-Aufnahmen im Browser werden unterstützt, und mehrere Dateien können in einem einzigen Connector zusammengefasst werden.
Klicken Sie im Datenquellen-Panel auf Audio, um einen neuen Audio-Connector zu erstellen:
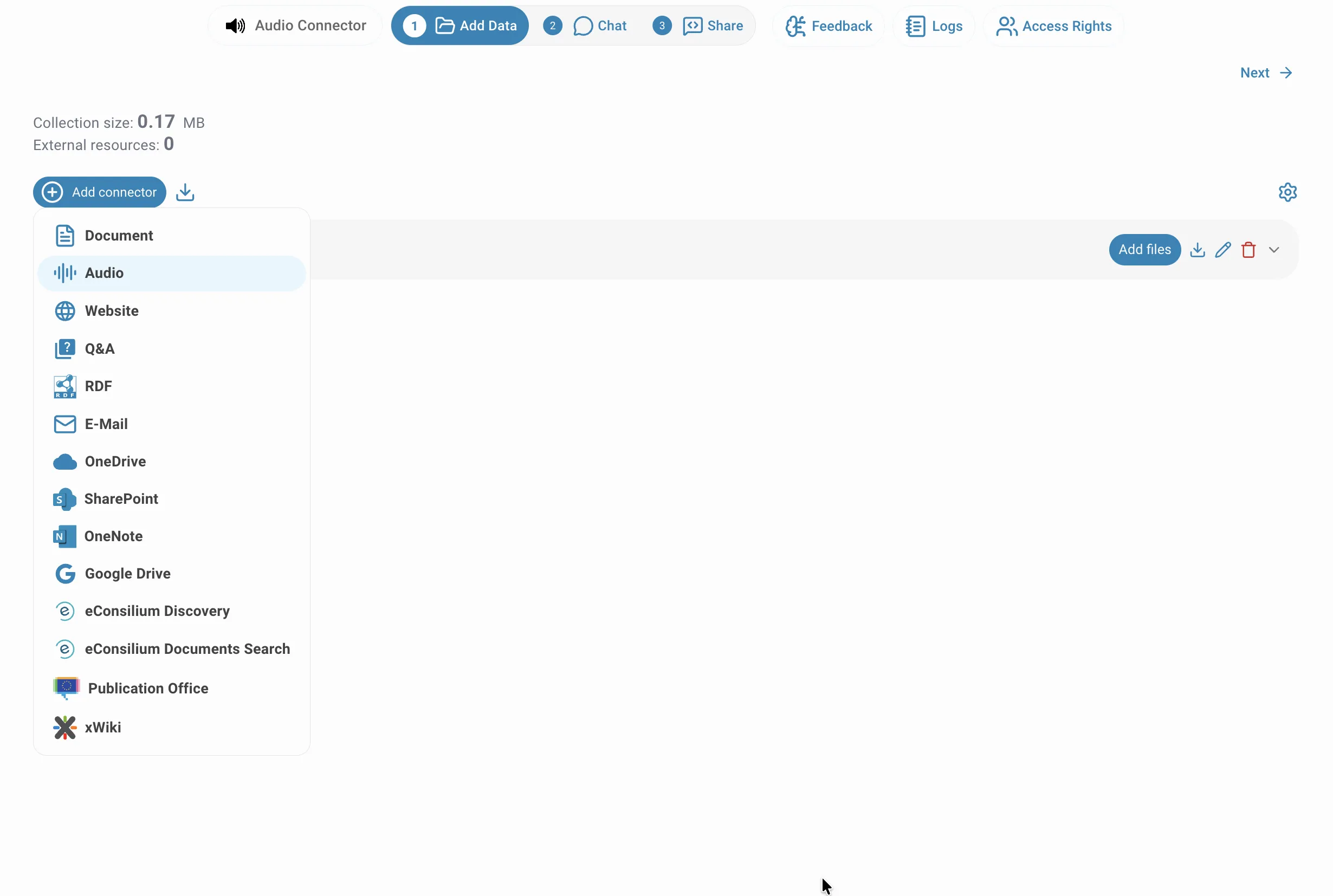
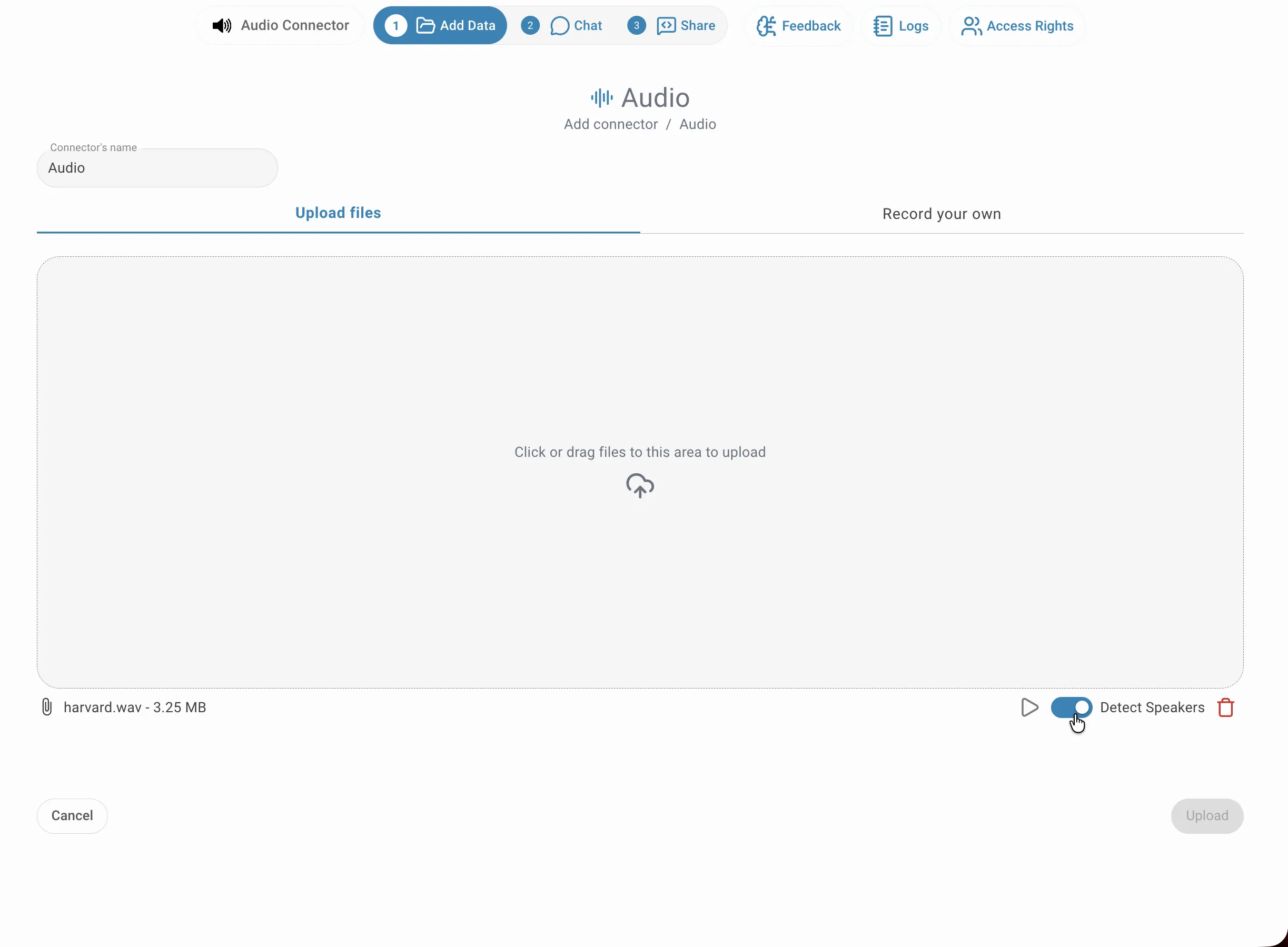
Dateien hochladen
Geben Sie Ihrem Connector einen Namen und ziehen Sie Ihre Audiodateien in den Upload-Bereich — oder klicken Sie hinein, um den Dateiauswähler zu öffnen. Sie können mehrere Dateien auf einmal hinzufügen. Jede Datei erscheint unterhalb der Ablagefläche mit Dateiname und Größe. Bevor Sie auf Hochladen klicken, können Sie die Diarisierung für jede Datei, die mehrere Sprecher enthält, individuell aktivieren.
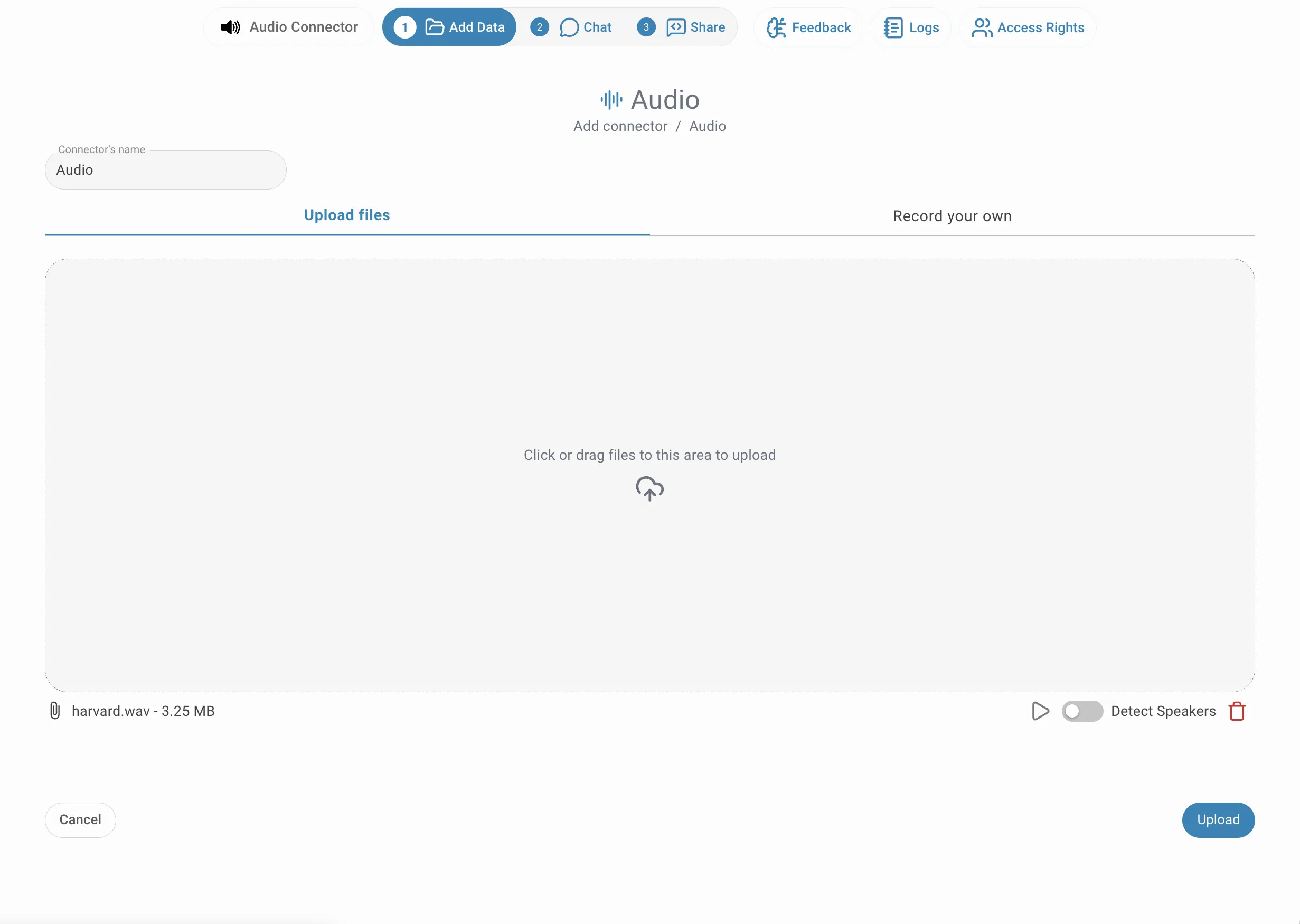
Aufnahme
Wechseln Sie zum Tab Eigene Aufnahme und klicken Sie auf Aufnahme starten, um Audio direkt im Browser über Ihr Mikrofon aufzunehmen. Eine Live-Wellenform bestätigt, dass die Aufnahme aktiv ist. Wenn Sie fertig sind, klicken Sie auf Aufnahme stoppen — das aufgenommene Audio wird gespeichert und genau wie eine hochgeladene Datei verarbeitet. Dies ist nützlich, um Live-Meetings, Sprachnotizen oder Interviews zu erfassen, ohne zuvor eine Datei speichern zu müssen.
Diarisierung (Sprechererkennung)
Um die Diarisierung für eine Datei zu aktivieren, klicken Sie auf den Schalter Sprecher erkennen auf der rechten Seite der Dateizeile. Der Schalter kann für jede Datei unabhängig gesetzt werden, sodass Sie innerhalb desselben Connectors einfache Transkription und Diarisierung kombinieren können — je nachdem, ob eine Aufnahme einen oder mehrere Sprecher enthält.
Die Diarisierung erkennt automatisch, wer zu welchem Zeitpunkt spricht, und unterteilt das Audio in beschriftete Segmente. Sprecher erhalten zunächst generische Bezeichnungen wie SPEAKER_00, SPEAKER_01 usw. — Sie können diese nach der Indizierung durch aussagekräftige Namen ersetzen. Verwenden Sie die Diarisierung für Interviews, Podiumsdiskussionen oder Aufnahmen, bei denen es für Ihre Abfragen wichtig ist zu wissen, wer was gesagt hat.
Wenn Ihre Dateien bereit und die Diarisierungseinstellungen konfiguriert sind, klicken Sie unten rechts auf Hochladen. Die Dateien werden sofort an den Server gesendet und die Transkription läuft im Hintergrund — Sie können die Seite verlassen oder an anderen Aufgaben weiterarbeiten, ohne zu warten. Durch das Verlassen der Seite geht kein Fortschritt verloren.
Warten auf die Indizierung
Nach dem Hochladen erscheinen die Dateien in der Dateiliste des Connectors und werden asynchron verarbeitet. Die Statusspalte aktualisiert sich, während jede Datei die Transkriptions-Pipeline durchläuft. Ein grünes Häkchen bedeutet, dass die Datei vollständig transkribiert und indiziert wurde und abgefragt werden kann. Schlägt eine Datei fehl, erscheint ein Fehlerindikator — fahren Sie mit der Maus darüber, um den Grund zu lesen. Sie können einem vorhandenen Connector jederzeit weitere Dateien hinzufügen, indem Sie auf Dateien hinzufügen in der Connector-Zeile klicken.
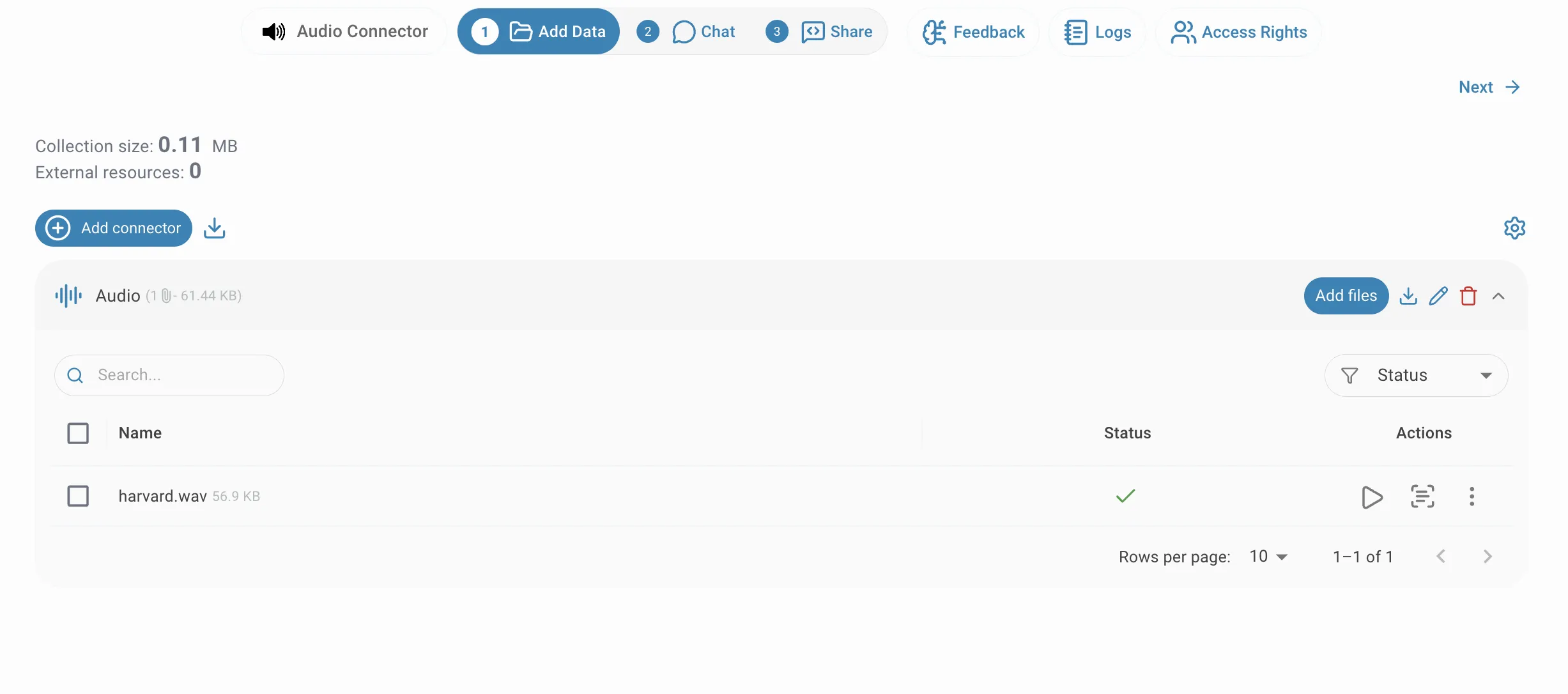
Transkription anzeigen
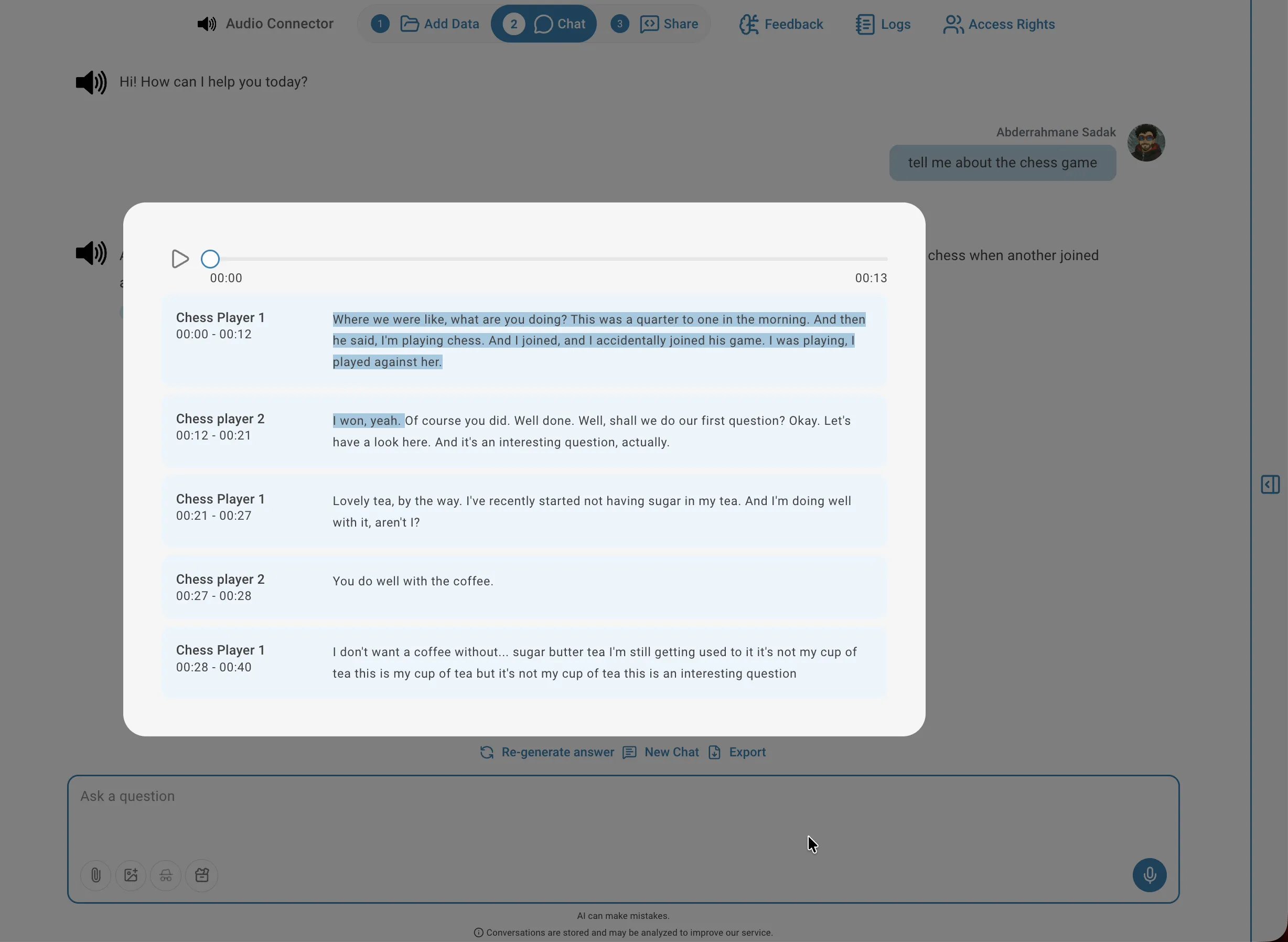
Um das Transkriptionsergebnis einer Datei einzusehen, klicken Sie auf das Transkriptions-Symbol in der entsprechenden Zeile der Connector-Liste. Der Viewer zeigt den vollständigen Text in Segmenten organisiert, jeweils mit Sprecher-Label (bei diarisierten Dateien), Zeitstempelbereich und dem transkribierten Text. Sie können das Audio ab einem beliebigen Segment durch Klick auf das Wiedergabesymbol daneben abspielen — nützlich zur Überprüfung der Genauigkeit oder zur Einordnung des Kontexts.
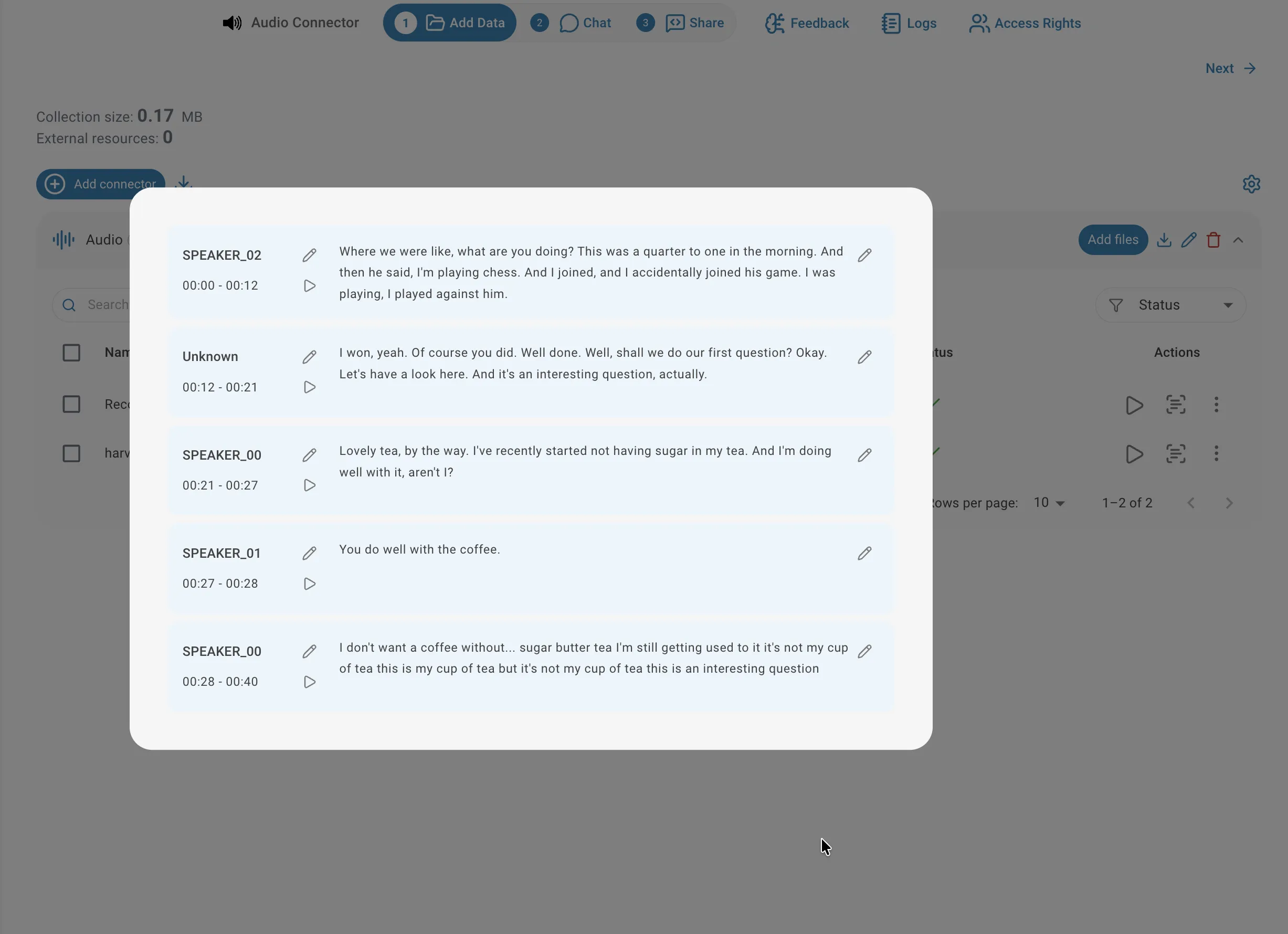
Audio anhören
Um das Audio für ein bestimmtes Segment anzuhören, klicken Sie auf das Wiedergabe-Symbol neben dem Segment:
Sprecher umbenennen
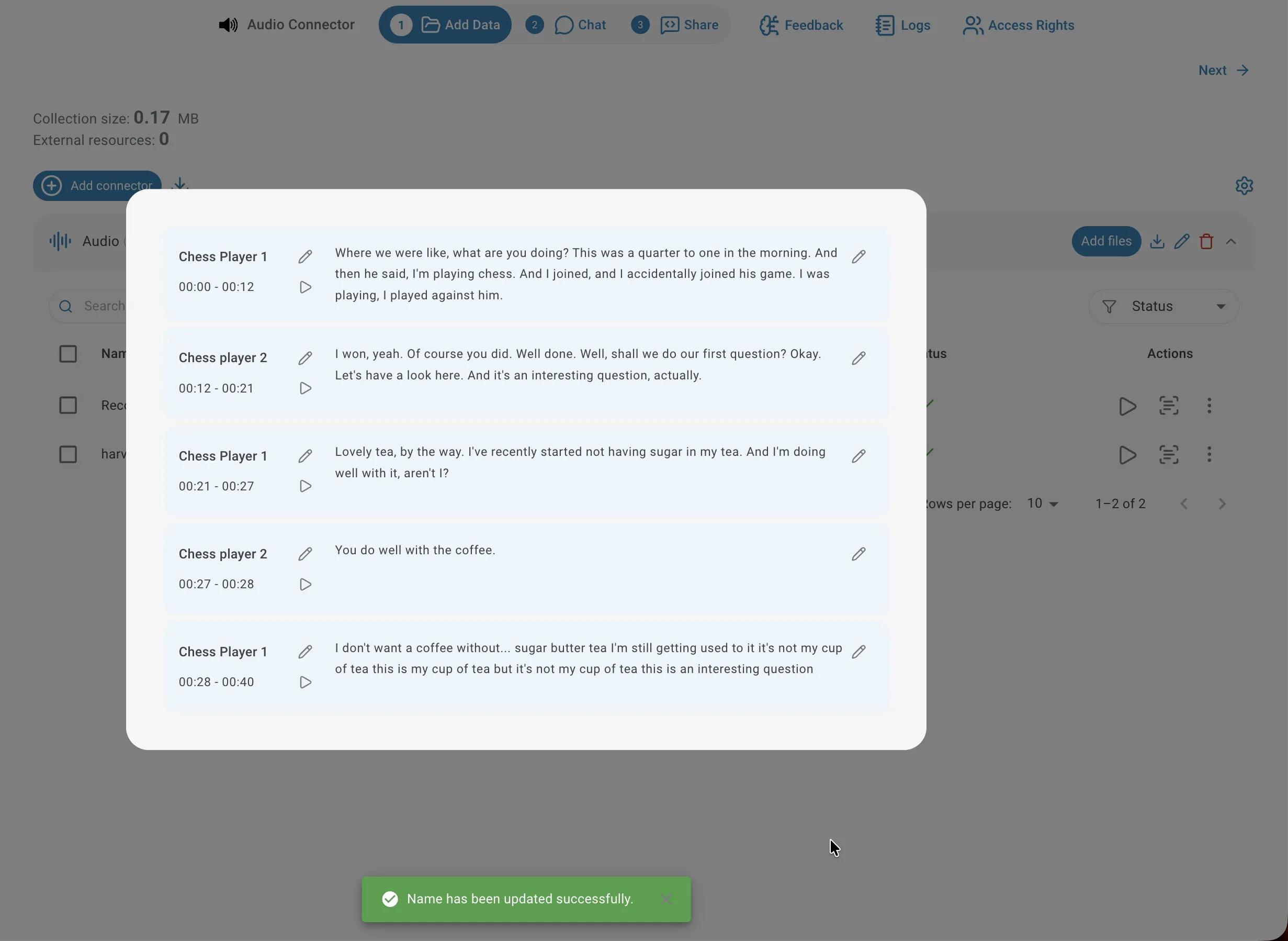
Automatisch vergebene Sprecher-Labels (SPEAKER_00, SPEAKER_01, …) können direkt im Transkriptions-Viewer durch echte Namen ersetzt werden. Klicken Sie auf das Bearbeiten-Symbol neben einem Sprecher-Label und geben Sie den neuen Namen ein. Sie werden gefragt, ob die Änderung auf alle Segmente dieses Sprechers in der gesamten Aufnahme oder nur auf das aktuelle Segment angewendet werden soll. Das Umbenennen von Sprechern macht Transkripte leichter lesbar und verbessert die Präzision von Antworten auf sprecherspezifische Fragen.
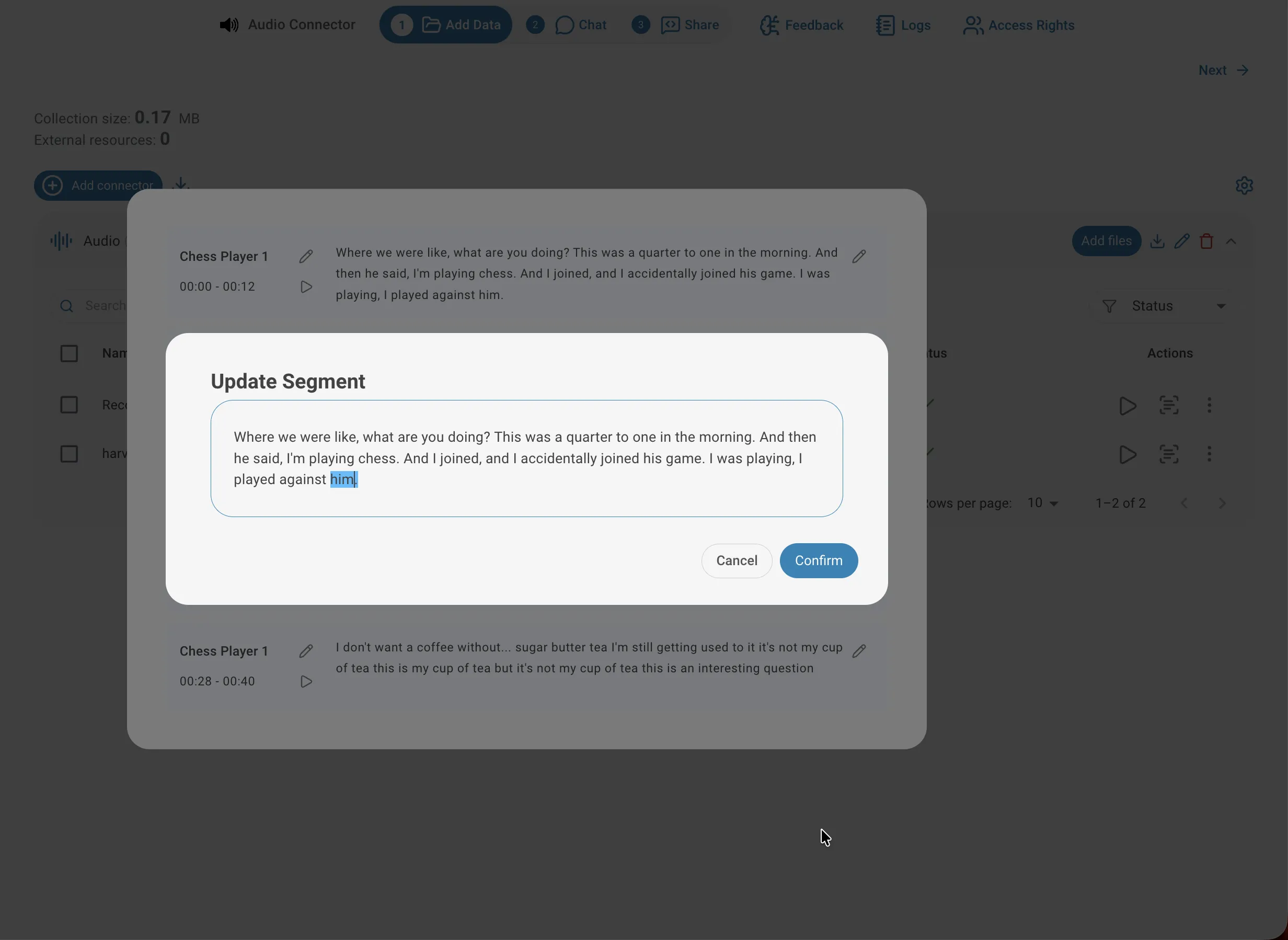
Segmenttext korrigieren
Die automatische Transkription kann gelegentlich Eigennamen, Fachbegriffe oder stark akzentuierte Sprache falsch erkennen. Um einen Fehler zu beheben, klicken Sie auf das Bearbeiten-Symbol rechts neben dem Segment, um den Dialog Segment aktualisieren zu öffnen, korrigieren Sie den Text und bestätigen Sie. Der aktualisierte Text wird sofort neu indiziert und bei allen zukünftigen Abfragen verwendet — das Korrigieren wichtiger Begriffe kann die Antwortqualität spürbar verbessern.
Fragen zu Ihrem Audio stellen
Sobald das Audio indiziert ist, wechseln Sie zum Chat-Tab, um in natürlicher Sprache Fragen zum Inhalt zu stellen. QAnswer durchsucht das vollständige Transkript und generiert eine Antwort, die auf dem tatsächlich Gesagten basiert. Sie können Sachfragen stellen wie 'Was war das Hauptthema der Diskussion?', eine Zusammenfassung einer Aufnahme anfordern oder einen bestimmten Sprecher abfragen, z. B. 'Was hat Anna über den Projekttermin gesagt?'. Der Assistent stützt sich ausschließlich auf das indizierte Transkript, sodass die Antworten präzise auf das Quellmaterial abgestimmt bleiben.
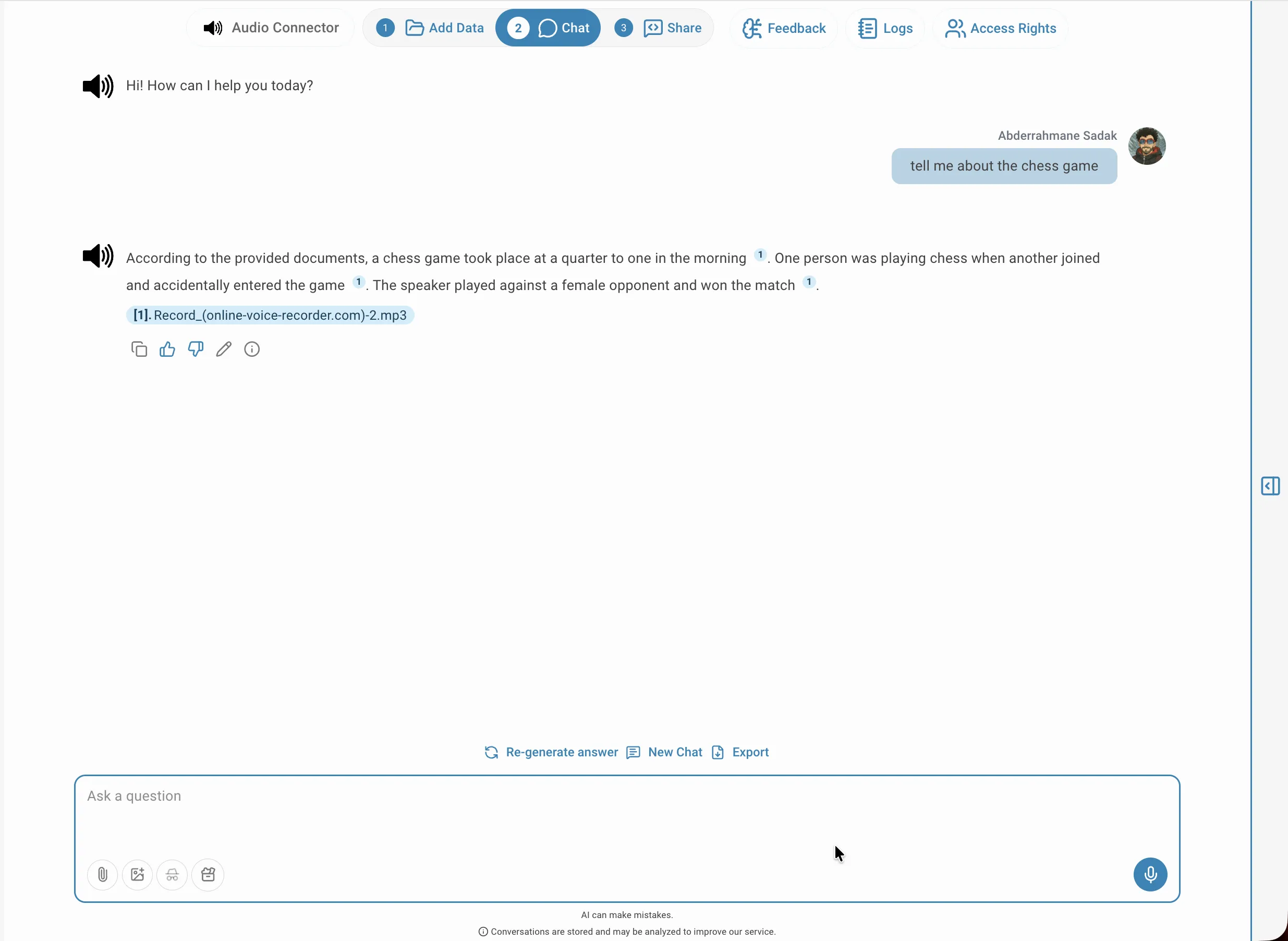
Hervorgehobene Quelle
Jede Antwort enthält nummerierte Zitate, die auf das genaue Segment im Transkript verweisen. Ein Klick auf ein Zitat öffnet den Transkriptions-Viewer mit dem hervorgehobenen Textabschnitt, einschließlich Sprecher-Label und Zeitstempel — so können Sie den Kontext überprüfen oder genau diesen Moment im Audio anhören. Dies erleichtert die Nachvollziehbarkeit von Antworten und die Erkennung etwaiger Transkriptionsfehler, die die Genauigkeit beeinträchtigen könnten.