Website - Data Source
Use a single webpage or an entire website as a data source. This section covers how to configure website crawling.
Click on Website to add a web page or a website as a data source:
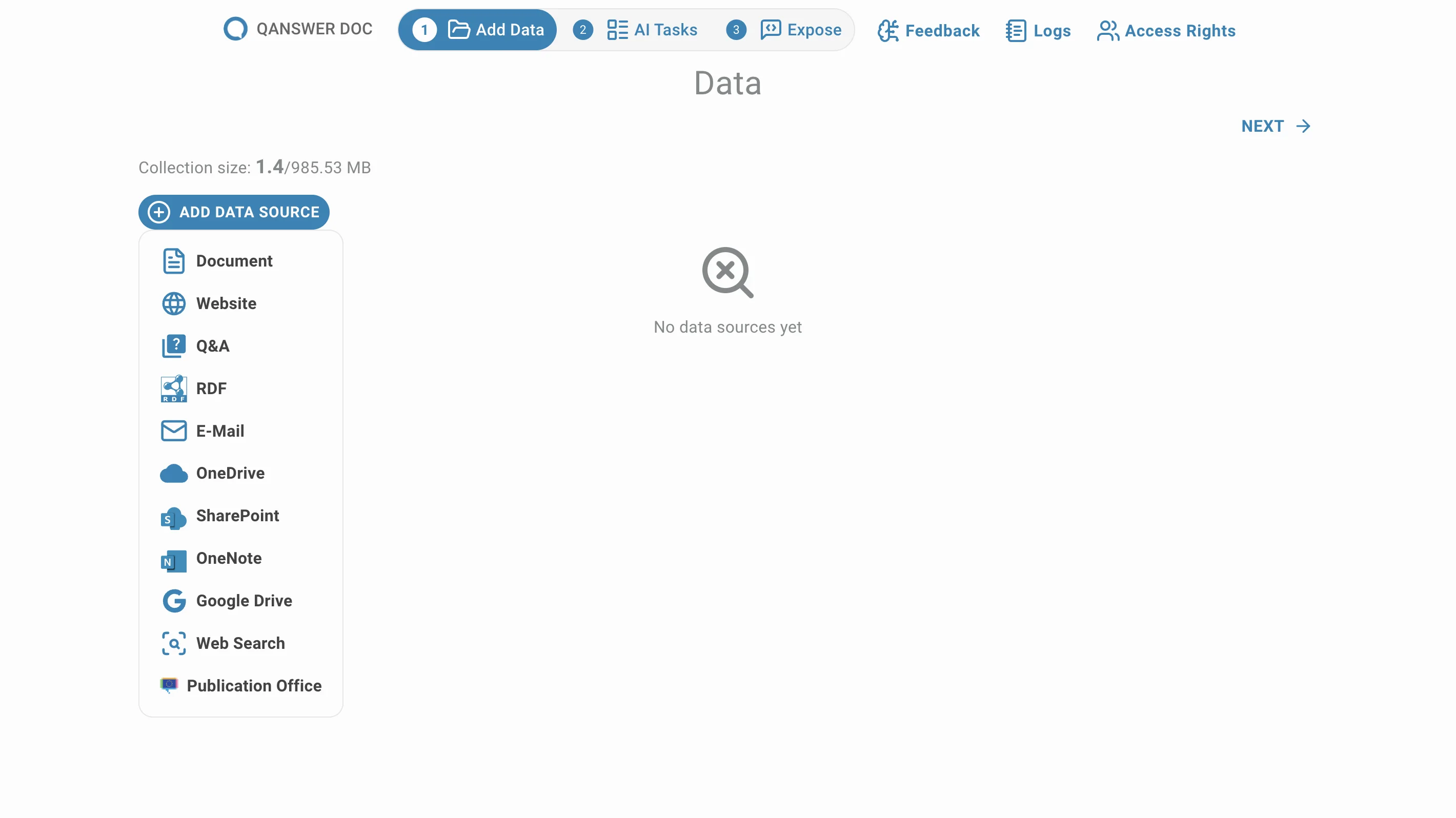
The following page opens:
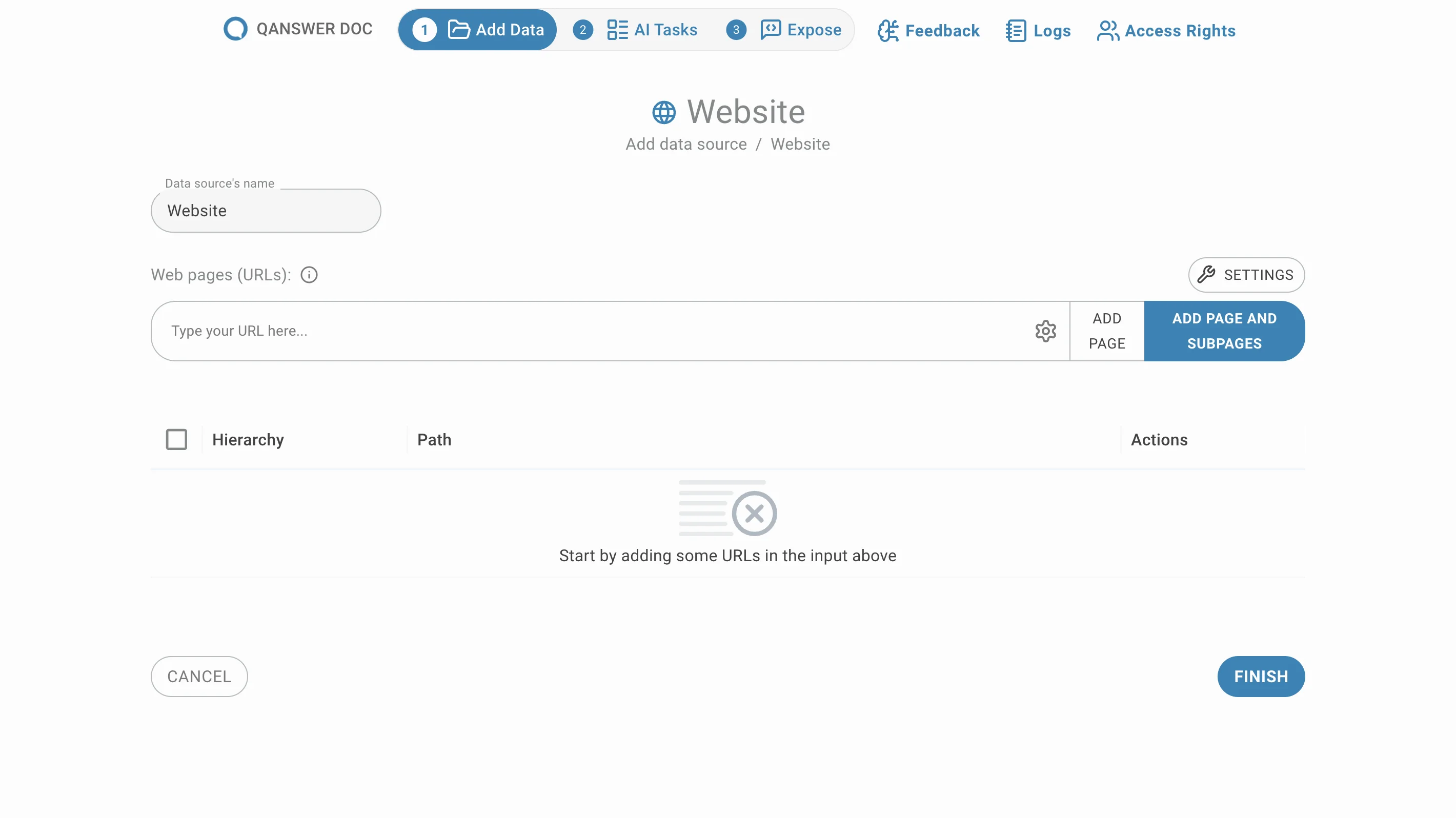
Add manually selected URLs
Enter the URLs of the pages you want to add and click on Add Page or press Enter. Your URLs will be appearing in the list below:
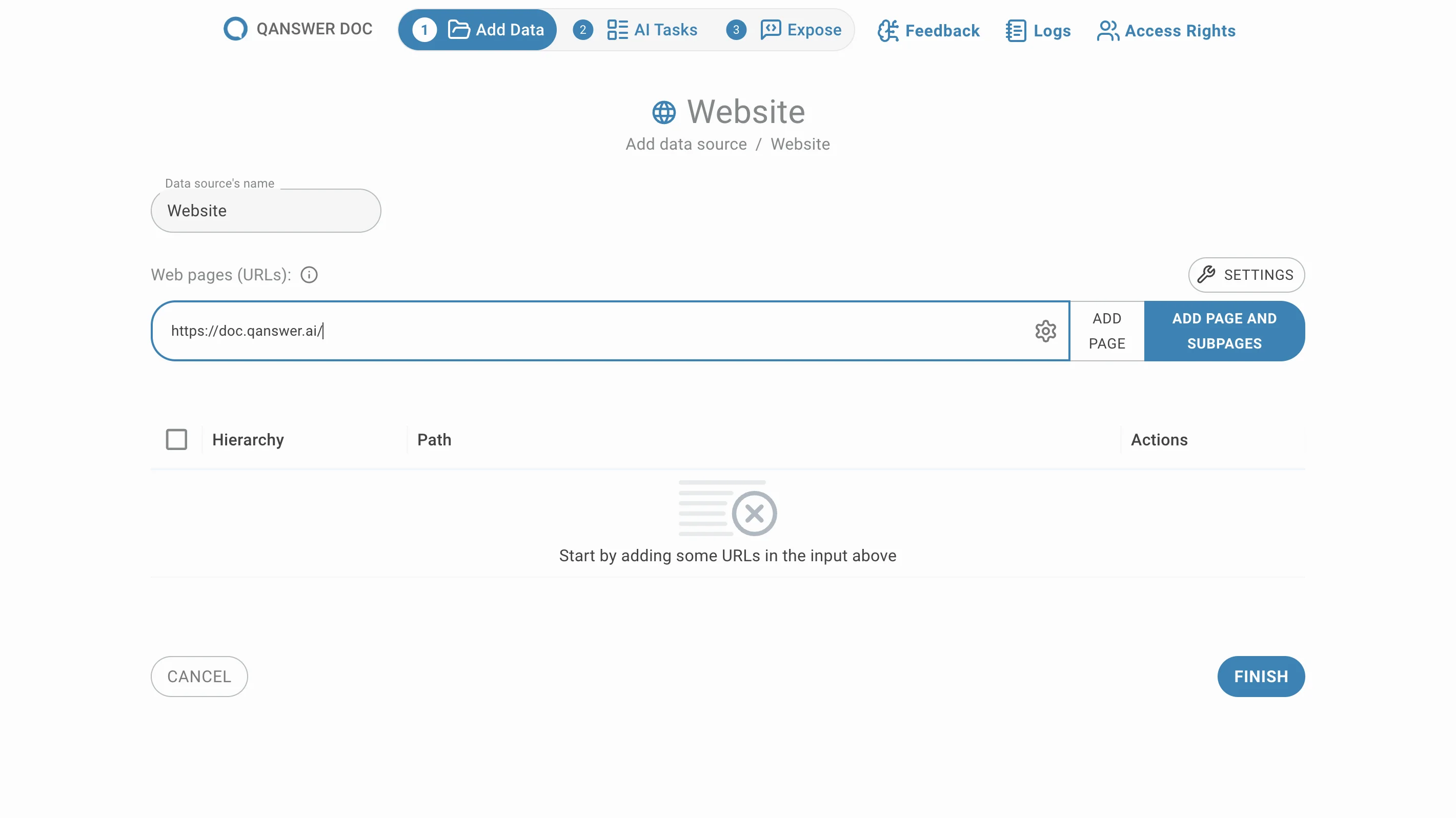
Crawl an entire website
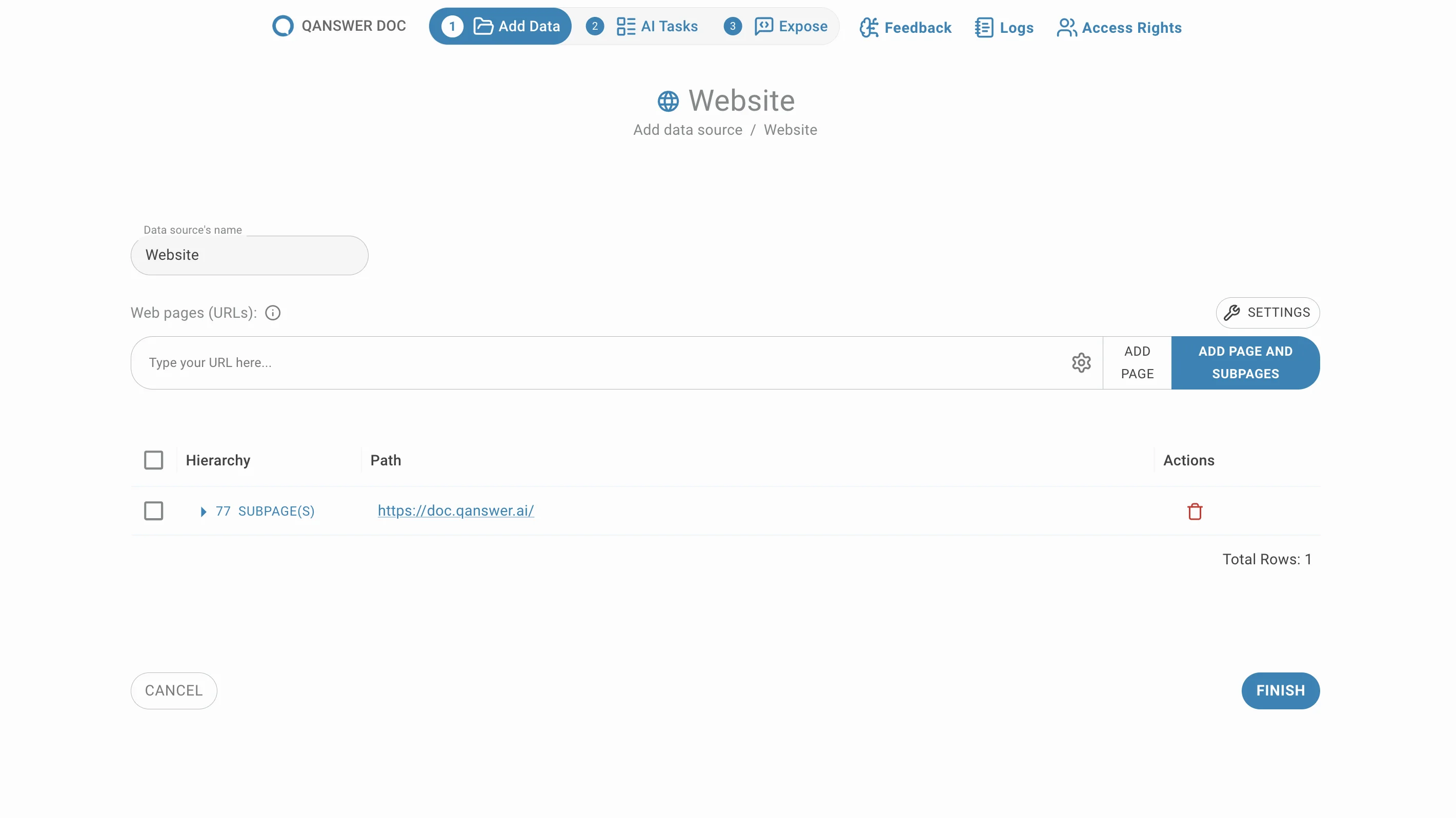
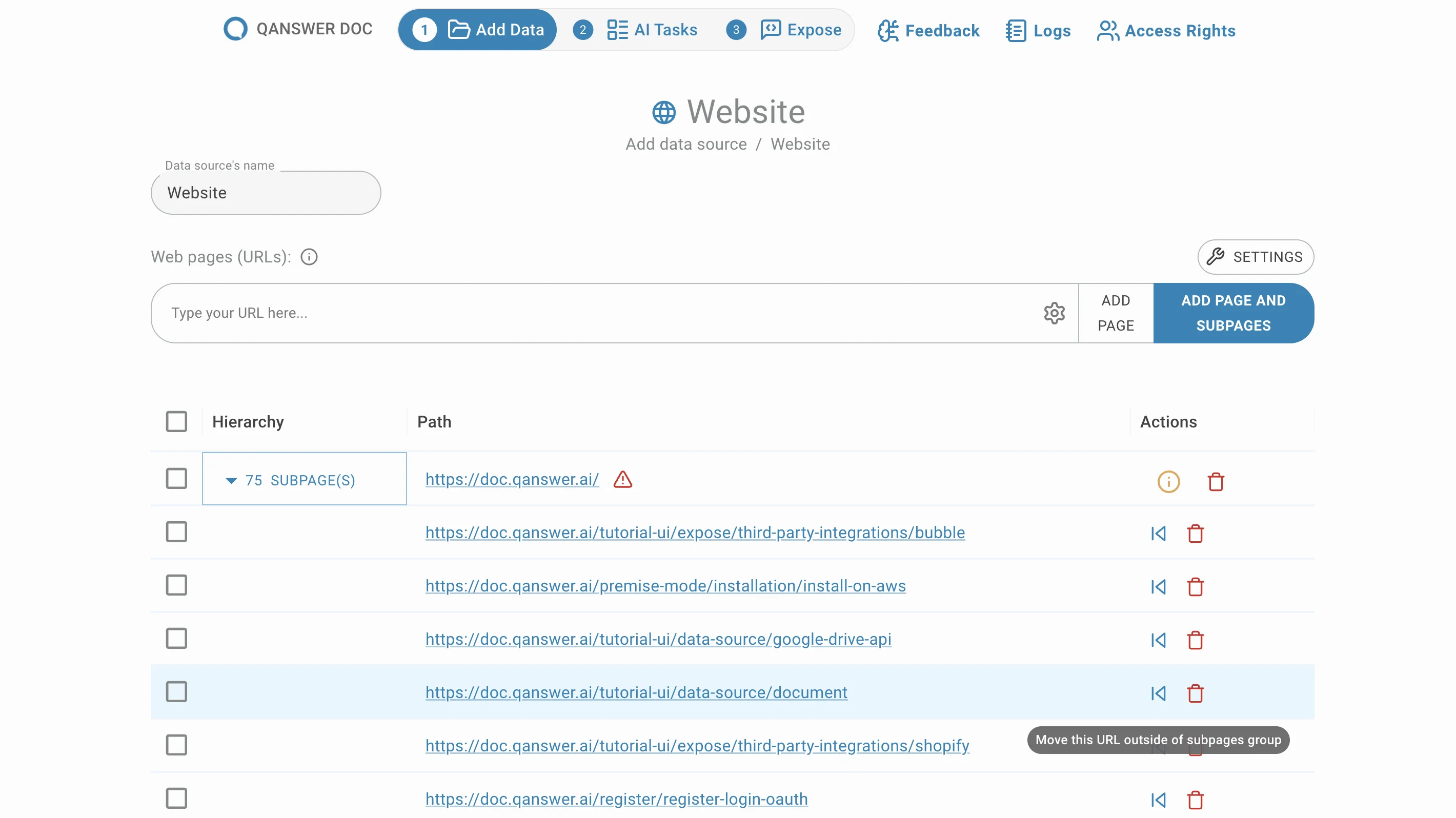
Enter the URL of a website and click Add Page and Subpages. All sub-pages under that URL are extracted and listed, grouped by default.
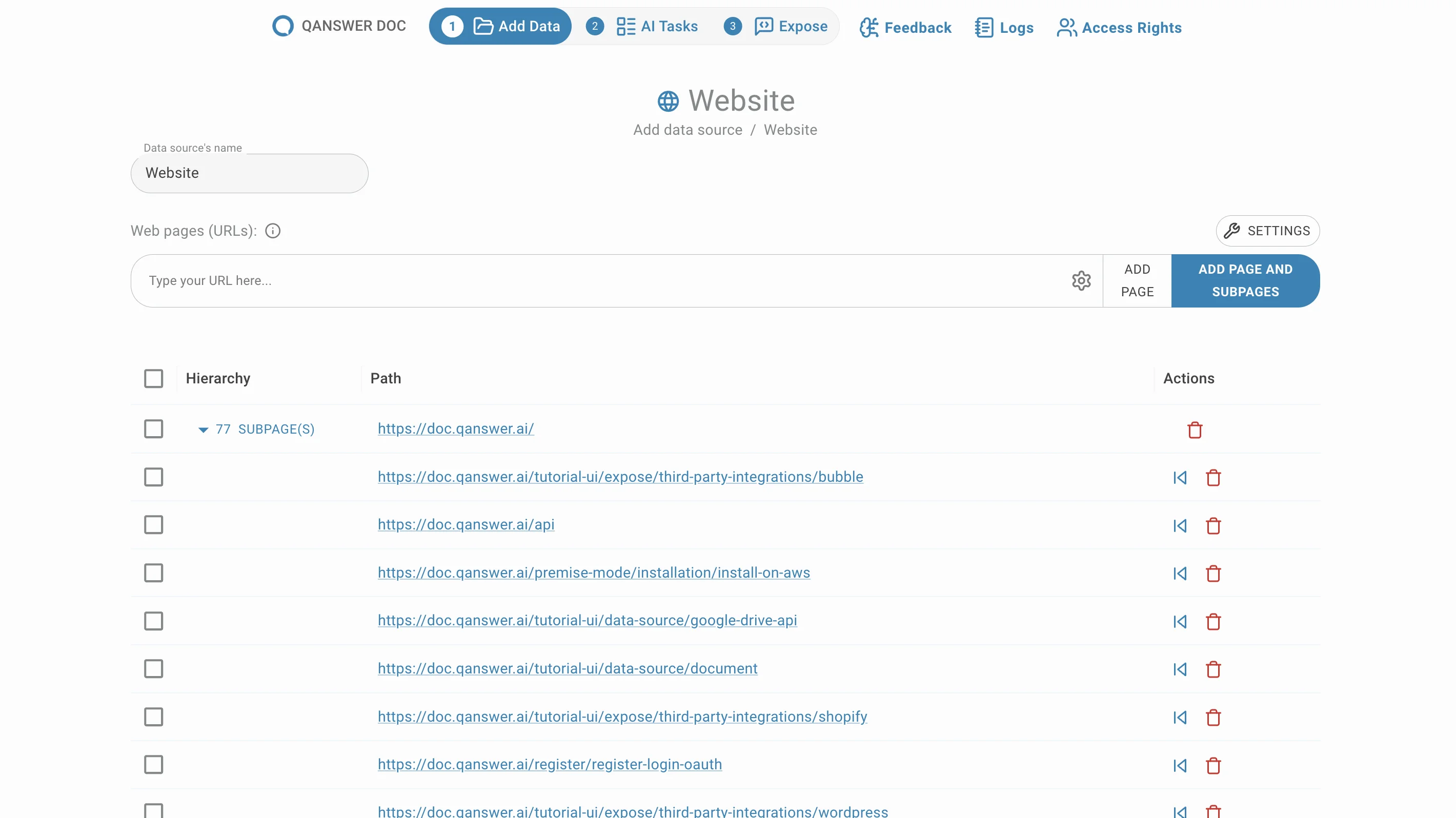
Delete sub-pages
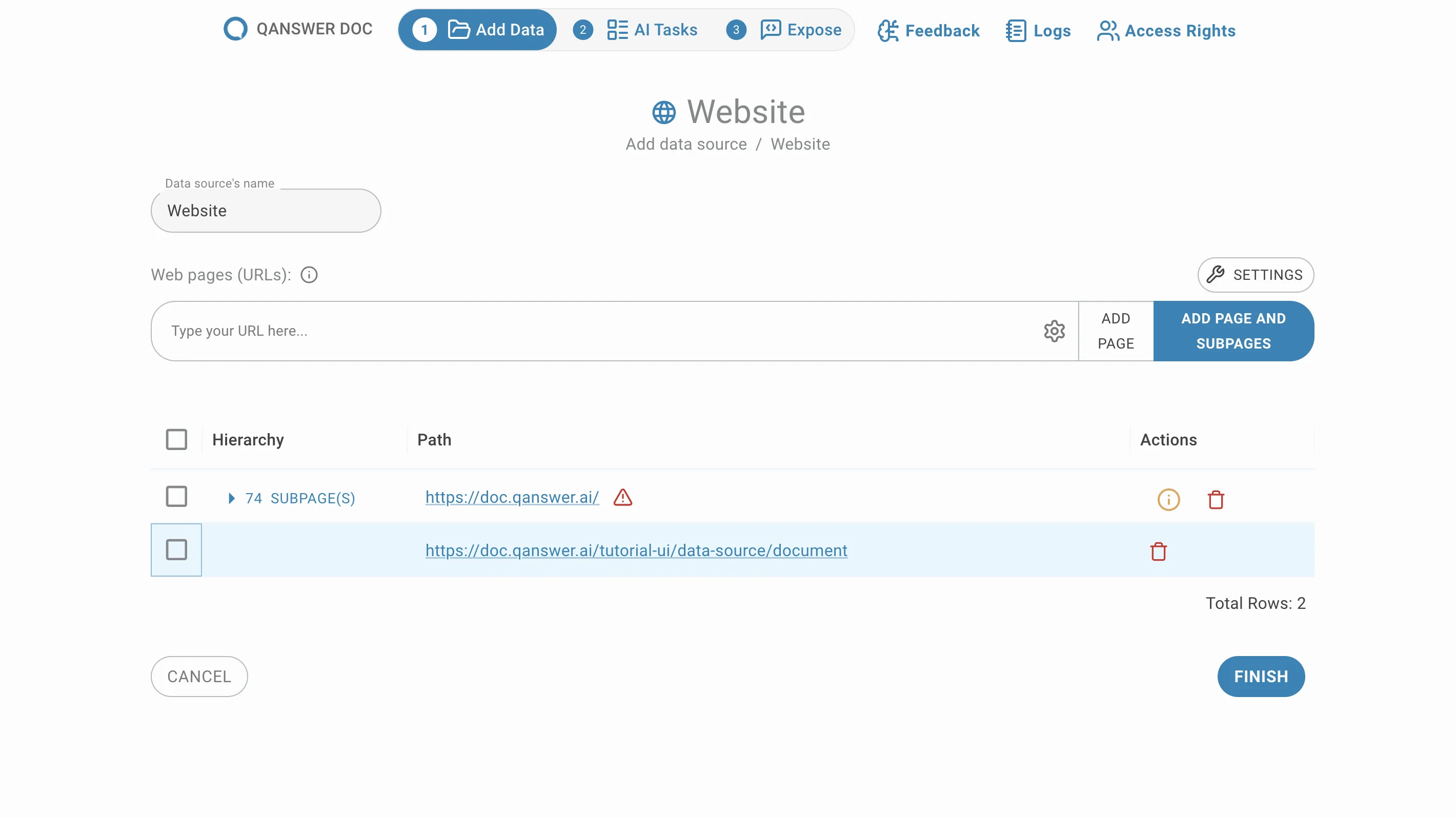
Remove unwanted sub-pages by clicking the delete button in the Action column.
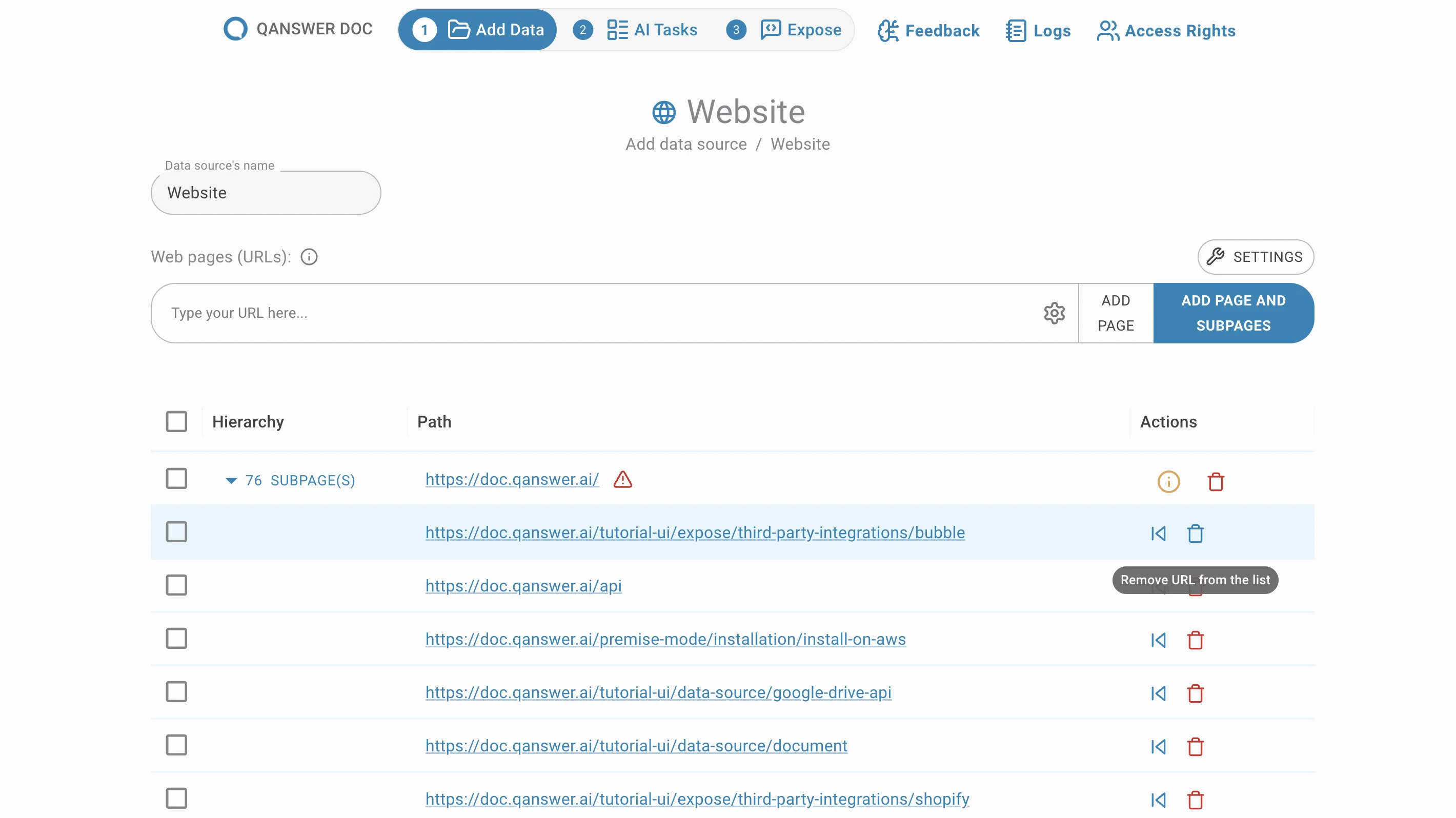
Move sub-pages
Sub-pages are grouped by default. Move them out of their group by clicking the Move button in the Action column.
Skipped Links Filtering
Overview
During link extraction, some URLs may be skipped — for example due to timeouts or website restrictions (such as robots.txt).
An info symbol may appear. By default, extraction skips links that do not contain the original URL, as these may belong to an external website.
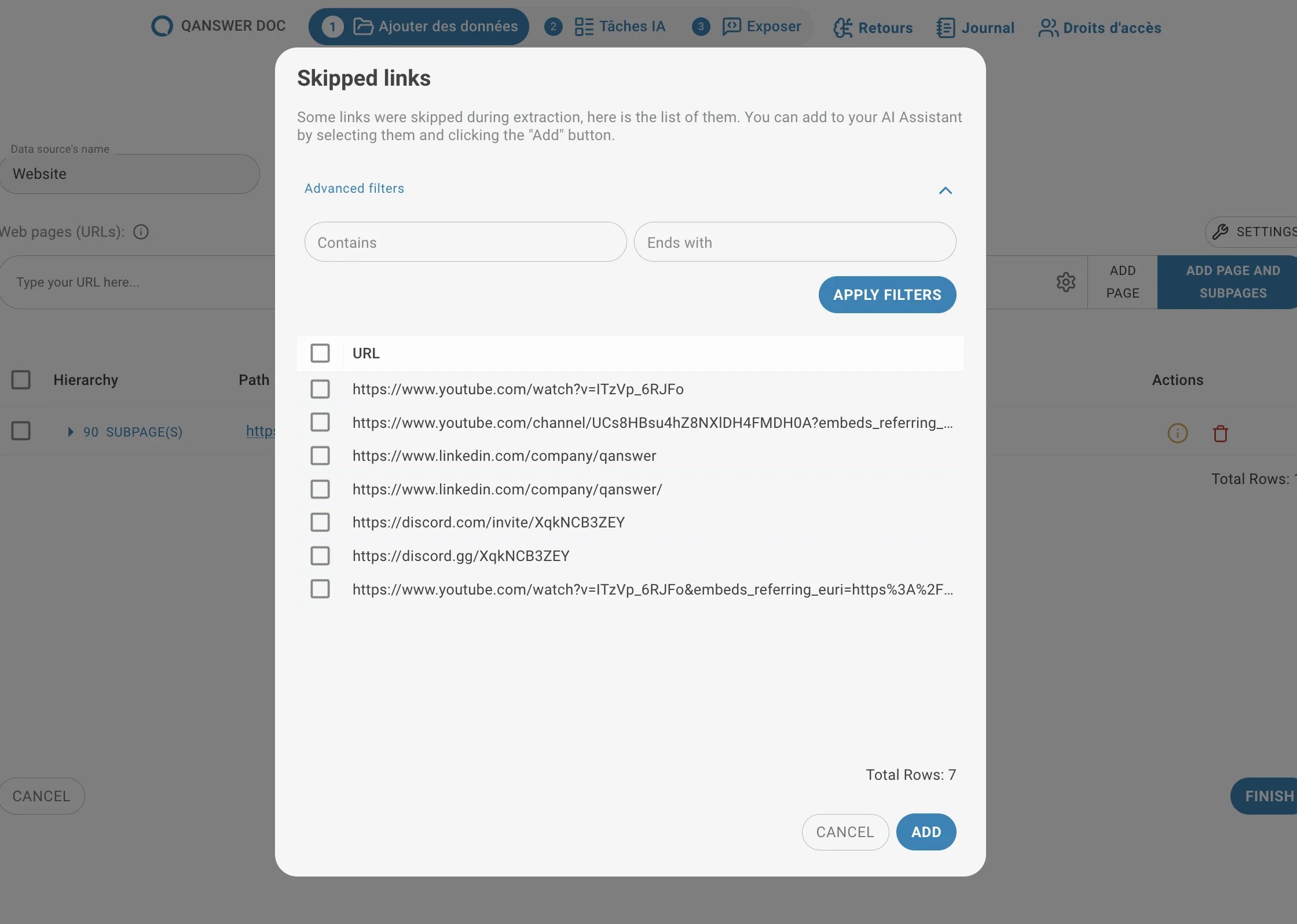
The Skipped Links modal lets you review these URLs and add them back into the dataset.
Two filters help manage large lists:
- Contains
- Ends with
These filters select groups of URLs based on simple text patterns.
How It Works
Enter a value in one of the filters:
- Contains — selects URLs that contain the provided substring.
Example: Filtering with "/blog/" selects all skipped links under a /blog/ sub-path (e.g., /blog/post-1, /blog/archive/...). - Ends with — selects URLs that end with the provided text.
Example: Filtering with ".pdf" selects all links pointing to PDF files. - Click Apply Filters.
All matching URLs are automatically selected.
Important Behavior: Additive Selection
Selections are additive.
Each new filter adds matching URLs to the current selection.
Manually selected URLs always remain selected.
New filters never remove previously selected URLs.
Example:
- Select URL 1 manually.
- Apply a filter matching URL 2 and URL 3.
- Final result: URLs 1, 2, and 3 are selected.
Advanced Settings (optional)
Customize the crawling parameters if needed. Default values suit most use cases. Available settings include:
Automatic Link Detection (Only for Extracting Hyperlinks)
- Maximum Depth: Controls how many levels deep the crawler follows links. A website is a tree of pages; this sets how far into that tree the crawler descends.
- Timeout: Sets the time limit for link discovery. The crawler stops early if this limit is reached.
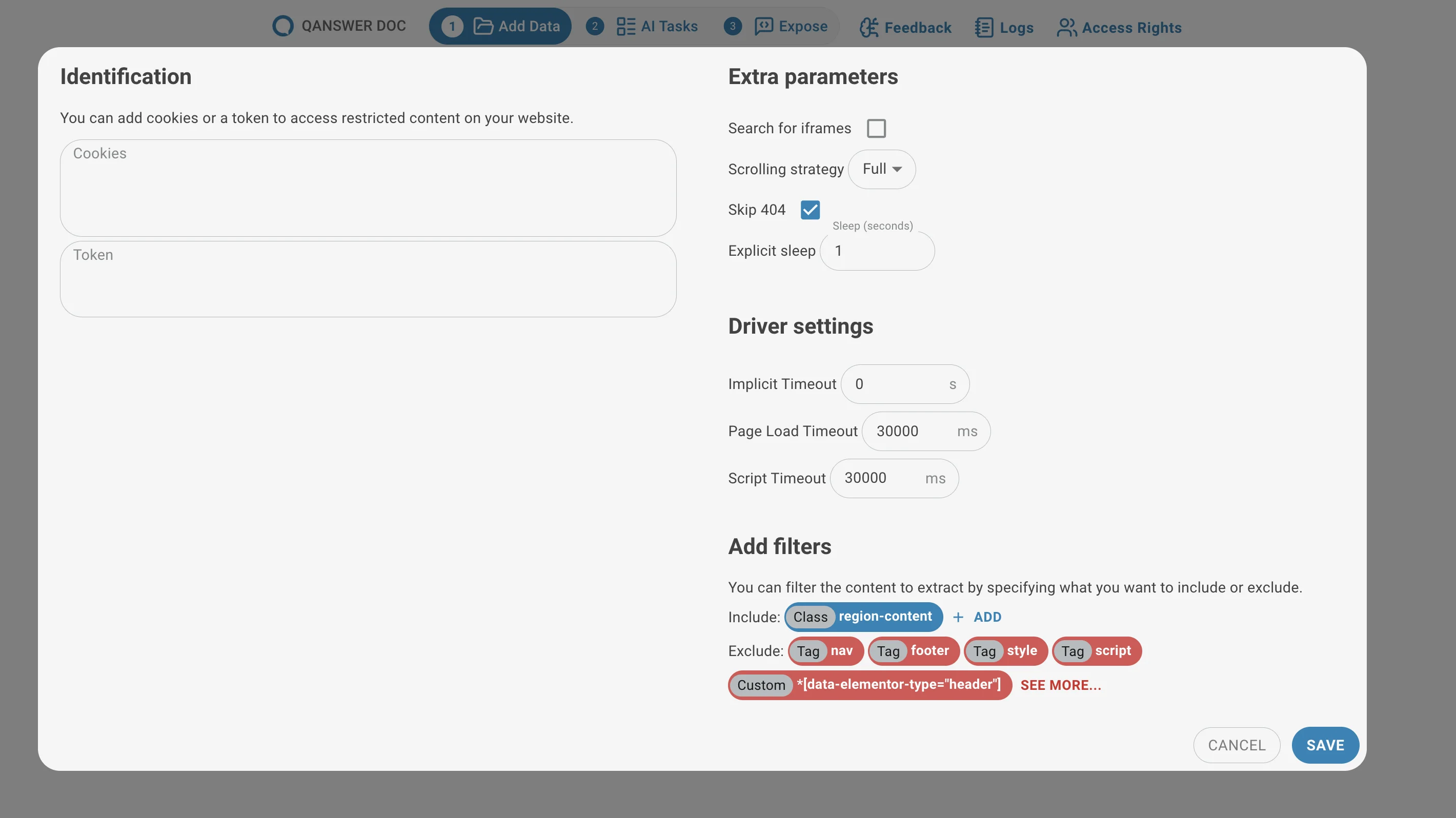
Authentication (For Both Link and Page Indexing)
- Cookies: Some websites require cookies for access. Provide them as a JSON dictionary.
{ "session": "abc123", "user_id": "789xyz" } - Token: Some websites require a token for access. The token name and value are written to the page's local storage and the page is reloaded.
{ "token_name": "Bearer your_token_here", }
Extra Parameters (For Both Link Extraction and Page Indexing)
- Search for Iframes: Controls whether the crawler inspects iframe content. Set to "auto" by default; can be forced on if needed.
- Scrolling Strategy: Controls how the crawler scrolls the page to trigger lazy-loaded content.
- Skip 404: When enabled, the crawler ignores broken links (404 errors) during link gathering instead of stopping.
Driver Settings (For Both Link Extraction and Page Indexing)
- Implicit Timeout: The fixed wait time before each page load attempt begins.
- Page Load Timeout: How long the crawler waits for a full page load, including images and JavaScript. Stops waiting when this limit is reached.
- Script Timeout: How long the crawler waits for JavaScript execution to complete before moving on.
Add Filters (For Both Link Extraction and Page Indexing)
- Include: HTML tags the crawler should focus on when gathering links or content (e.g.,
<div>,<a>). - Exclude: HTML tags or sections the crawler should ignore (e.g.,
<script>,<footer>).
Create
Click Finish to go to the data source page. The selected pages begin crawling immediately.
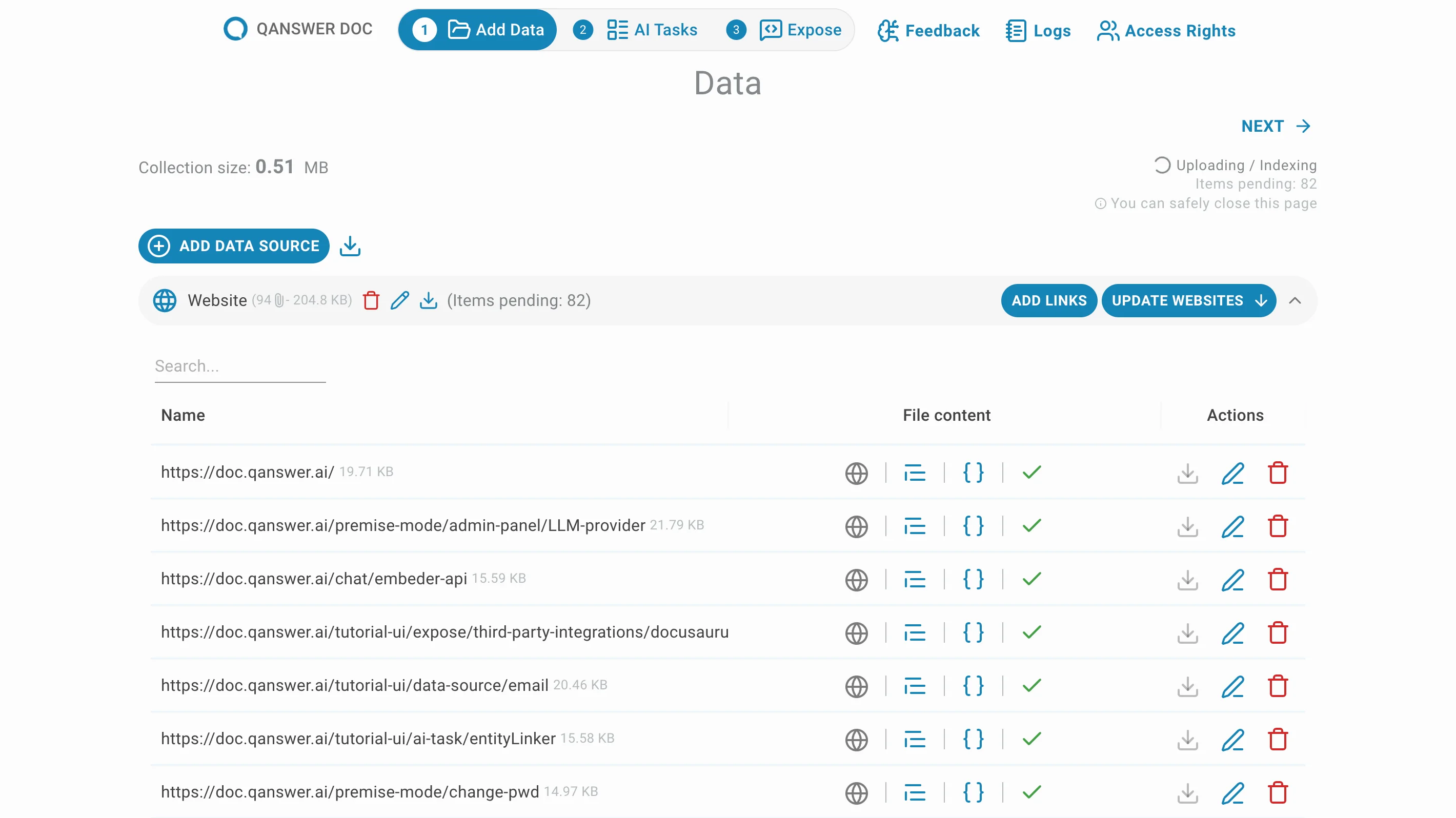
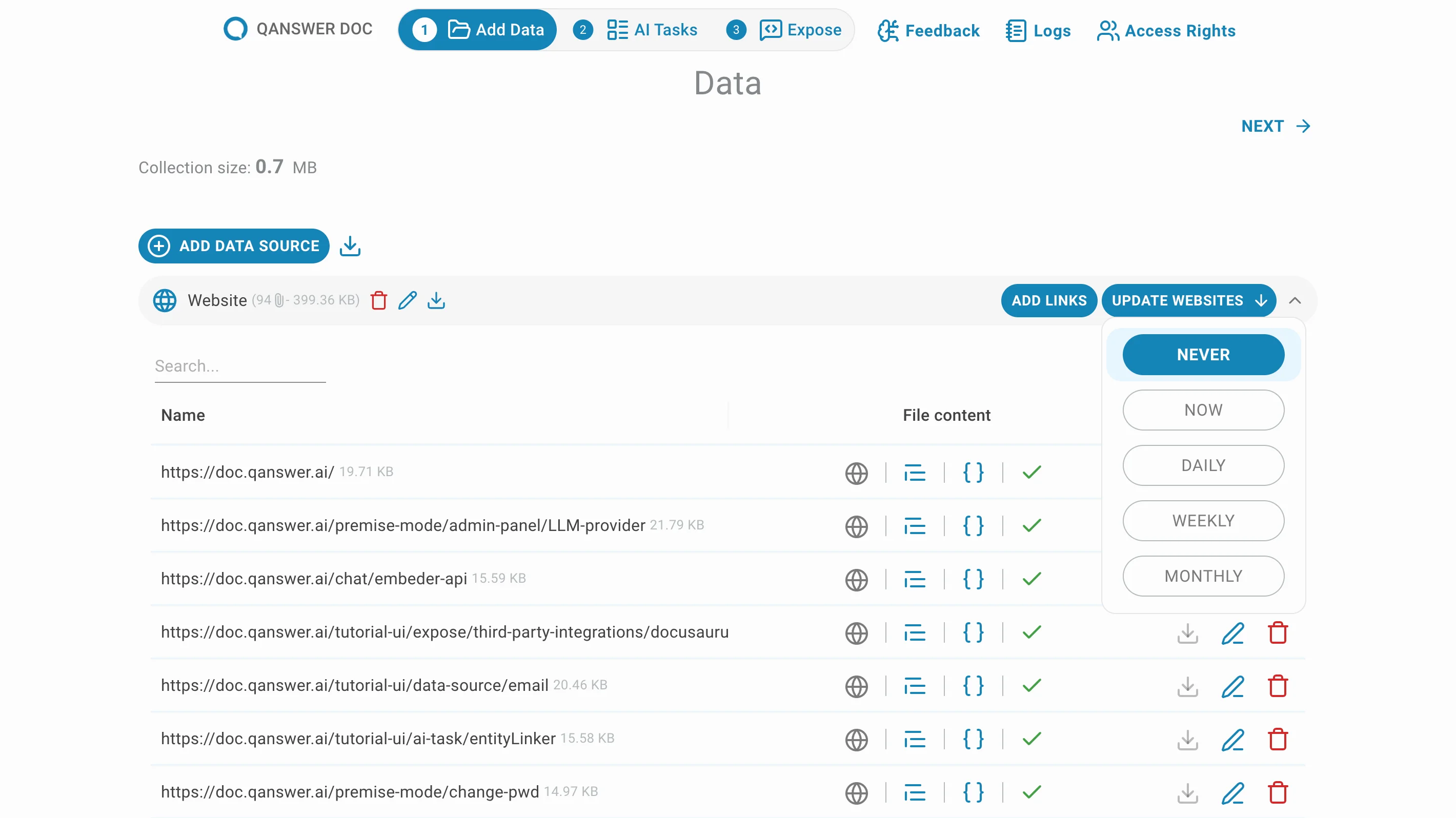
Click Update Websites to set the frequency of automatic crawling updates.
Batch Actions on Selected Links
You can select multiple links at once using the checkboxes on the left side of each row.
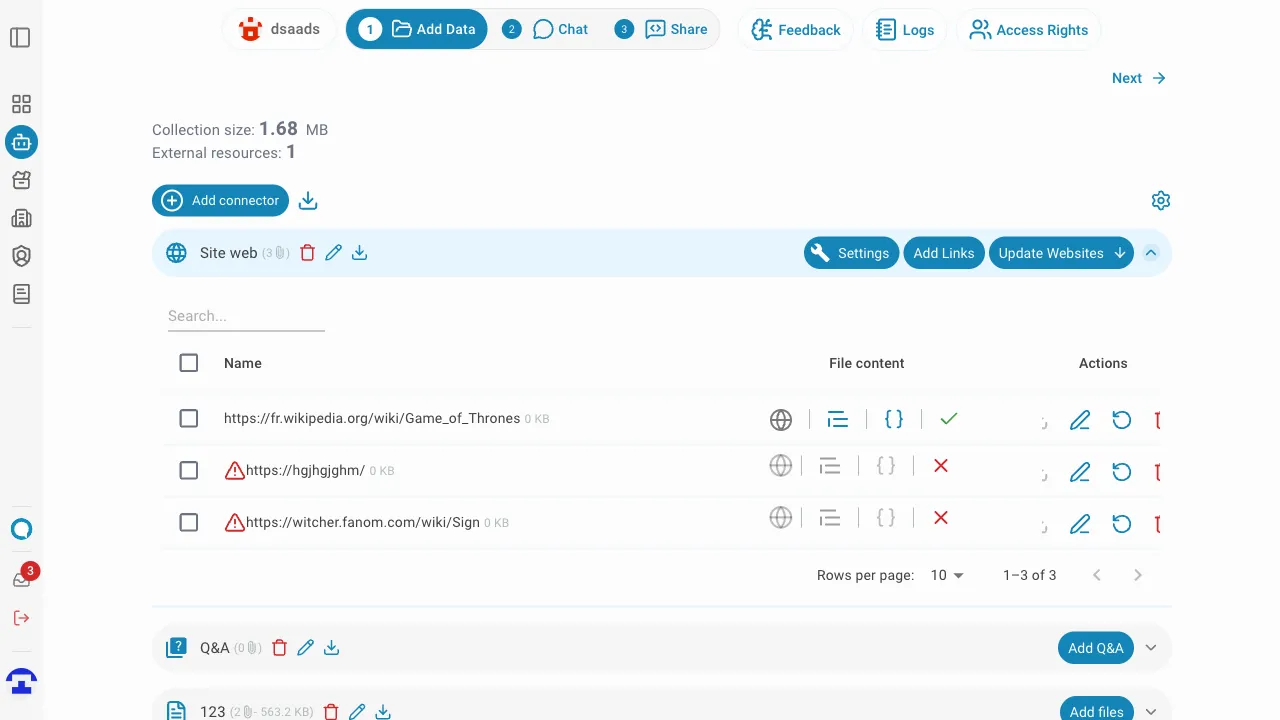
Once one or more links are selected, a batch action toolbar appears above the table with the following actions:
- Retry selected links — re-crawls all selected website links in parallel. Useful for re-indexing links that previously failed or need to be refreshed.
- Delete — permanently removes all selected links from the connector.